Figure 2.1: Example of a hierarchical IP network structure.
Host Configuration and Robustness in the Internet Protocol version 6
CSC 591: Directed Studies with Dr. Michael Miller
B. Cameron Lesiuk
August 14, 1998
Department of Mechanical Engineering
University of Victoria, Victoria, BC, Canada
Preamble:
This report was written in partial fulfillment of a CSC 591 Directed Studies course with my supervisor, Dr. Miller. This report was written in Frame Builder and later translated into HTML form.
Click here to return to my home page.
This report analyzes the Internet Protocol version 6 with a focus on configuration and robustness. The scope of the report is limited to presenting key host configuration and robustness issues, complemented with a modest evaluation of their design. The Internet Protocol architecture is presented for background information. Host autoconfiguration and Mobile IP principles are presented. Except for some minor weaknesses in the autoconfiguration process, the Internet Protocol promises to be extremely robust and flexible.
Table 2.1: Examples of IPv6 addresses representation .
Figure 2.1: Example of a hierarchical IP network structure.
Figure 2.2: Example of an IP network with a loop.
Figure 2.3: IPv6 packet header format.
Figure 4.1: Illustration of an IPv6 tunnel.
Figure 4.2: Illustration of bi-directional tunneling.
Figure 4.3: Illustration of a mobile and correspondent node communicating through a home agent.
This report analyzes the Internet Protocol version 6 (IPv6) for its configuration and robustness attributes. Specifically, on-the-fly configuration and fault tolerance is emphasized. To this end, this report is broken down into thee main sections. First, the general IPv6 architecture and underlying philosophies are reviewed; IPv6 concepts required in later sections are introduced. Secondly, host configuration procedures are analyzed. This section analyzes how IPv6 is designed to respond to new or mobile hosts. Lastly, host mobility is analyzed. This section focuses on how IPv6 maintains network connectivity for nodes despite changes to network topology.
At this point, it is important to note the difference between the terms node, host, and router as used in this report. A node is any device which implements IPv6 and maintains a presence on the network. A router is any node that forwards IP packets not explicitly addressed to itself. A host is any node that is not a router; a host initiates packets and receives packets addressed to itself. The distinction between these terms is important where host autoconfiguration is discussed in section 3.
In order to provide sufficient technical detail, and yet remain within the size constraints of this report, the scope of this report has been limited. There exists under IPv6 extensive configuration mechanisms and robustness issues. However, this report has been limited to an analysis of the configuration and robustness of hosts operating in IPv6 networks. Special nodes such as routers and servers are mentioned where relevant, but an analysis their configuration and robustness is beyond the scope of this report. Special considerations for security and cryptographic purposes are also considered beyond the scope of this report and are omitted.
The overall goal of the Internet Protocol is connectivity. The Internet is composed of millions of computers all connected together by a single global network. Designing a network protocol which scales to millions of nodes, and yet remains simple enough to implement on memory-starved microcomputers, is non-trivial. This section presents the basic IPv6 network architecture, packet format, and policies relevant to this report.
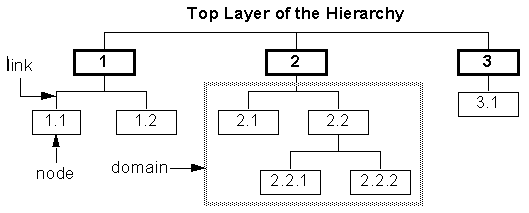
In its simplest form, an Internet Protocol (IP) network is arranged as a hierarchy as illustrated in Figure 2.1 [1]. Note each layer of the hierarchy has its own portion of the address space allocated to it; all nodes below a given network layer share the same subnet prefix. Networks which share a subnet prefix are said to be in the same domain. A network medium which directly connects to one or more nodes is called a link.
If a source node wishes to send a packet to a destination node, but the two nodes are not directly connected by a link, the packet is transmitted to the next closest node to the destination.
Figure 2.1: Example of a hierarchical IP network structure.
For example, in Figure 2.1, if node 2.2.1 sends a packet to node 3.1, the packet is sent node 2.2, 2, 3, and then finally to 3.1 respectively. The process of forwarding packets from one node to the next towards the final destination is called routing. In this example, each node along the packet’s path routes the packet to the next appropriate node. Routing forms the basis of network connectivity and enables any two nodes on the network to exchange data.
The objective behind the use of hierarchical routing is to achieve some level of routing data abstraction. This reduces CPU, memory, and transmission bandwidth consumed in support of routing.
If nodes and domains were connected in a more-or-less random (i.e. non-hierarchical) scheme, it is quite likely no routing data abstraction could occur. Since domains would have no defined hierarchical relationship, IPv6 addresses could not be assigned out of some common prefix for the purpose of routing data abstraction. The result would be flat routing; all nodes would need explicit knowledge of all other nodes they route to.
This can work well in small and medium sized networks. However, this does not scale to very large networks. For example, IPv6 is expected to support hundreds of thousands of domains and millions of nodes. This requires a greater degree of routing abstraction to make network implementations possible.
While practical IPv6 networks are not expected to be strictly hierarchical, for the purposes of routing data abstraction they are intended to be mostly hierarchical. Figure 2.2 illustrates a more practical IPv6 network which is mostly hierarchical. In this case, the top layer of the network breaks the hierarchy model and contains a loop.
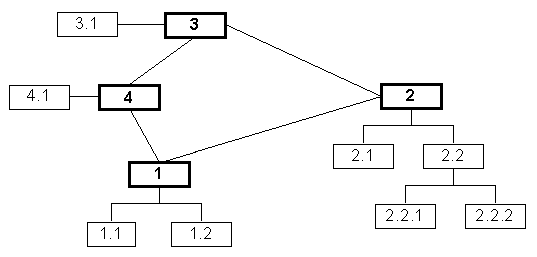
Figure 2.2: Example of an IP network with a loop.
In order to decide where packets should be sent, IP networks utilize routing tables and routing algorithms. In Figure 2.2, node 1 can send packets to node 3 via either of nodes 2 or 4. Node 1 may, by default, send packets to node 3 via node 2. However, should the link between 1 and 2 be severely congested or fail altogether, node 1 may dynamically decide to send packets to node 3 via node 4.
IPv6 addresses are 128-bit identifiers for interfaces. There are three types of addresses: unicast, anycast, and multicast [5]. A unicast address is a unique identifier assigned to a single interface. A packet sent to a unicast address is delivered to the interface identified by that address. An anycast address is a unique identifier assigned to many interfaces. A packet sent to an anycast address is delivered to the closest interface identified by that address. A multicast address is also a unique identifier assigned to many interfaces. However, a packet sent to an multicast address is delivered to every interface identified by that address. This report deals mainly with unicast addresses; unless otherwise specified, it is implied addresses are unicast.
It is useful to note IPv6 does not have a broadcast address. Instead, a special multicast address is used to send packets to all interfaces connected to a link.
IPv6 addresses are assigned to interfaces, not nodes. Since each interface belongs to a single node, any of that node’s interfaces’ addresses may be used as an identifier for the node [5]. A single interface may, however, be assigned multiple IPv6 addresses.
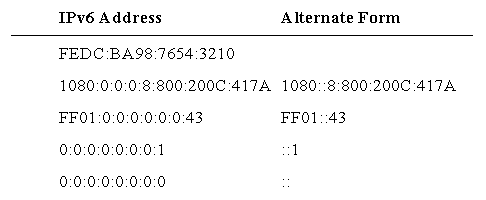
The conventional form for representing IPv6 addresses is as a series of eight 16-bit hexadecimal values separated with a colon ":" (see Table 2.1). It will be common for addresses to contain long strings of zero bits. In order to make writing addresses containing zero bits easier, a special syntax is available to compress the zeros. The use of "::" indicates multiple groups of 16-bits of zeros. The "::" can only appear once in an address. The "::" can be used to compress the leading and/or trailing zeros in an address.
Table 2.1: Examples of IPv6 addresses representation [5].
Portions of the IPv6 address space have been allocated for unicast addresses, multicast addresses, and special purpose addresses. Anycast addresses are allocated from the unicast address pool. The bulk of the address space, roughly 85%, remains reserved for future use. Addresses are bit-wise maskable; any bit in the 128-bit address may represent a domain prefix boundary.
An exhaustive examination of the IPv6 packet format is beyond the scope of this report. It is useful, however, to briefly present the relevant components of the IP packet. The complete IPv6 packet format specification can be found in [4].
The IP packet is composed of two parts: the packet header and the payload. The payload is the actual data which is being transmitted from the source to the destination. The header is added to the start of the packet and contains special information about the packet. The information in the header is sufficient for routers to decide how the packet should be handled. Figure 2.3 illustrates the format and fields of the packet header. The fields relevant to this report are the source and destination addresses and the next header field.
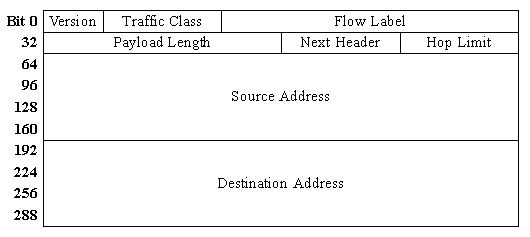
Figure 2.3: IPv6 packet header format [4].
The source and destination address fields contain the full 128-bit IP addresses assigned to the source network interface and destination network interface. The next header field indicates the presence and type of optional header extensions. Header extensions are subsequent header fields included after the packet header but before the payload. Any number of header extensions may be attached to an IPv6 packet header and serve a variety of purposes. In this report, header extensions are indicated in boldface. For example, neighbor solicitation and neighbor advertisement extensions are special messages used during host autoconfiguration.
When new hosts are added to an IPv6 network, they must be discovered and configured. Permanent or non-mobile hosts are usually configured manually when they are added to the network. For mobile or temporary hosts, however, it is often undesirable or impossible to manually configure the host. This section describes the facilities under IPv6 which can be used to automatically discover and configure a new host on the network. This section deals only with configuring the host to achieve IPv6-layer network services. Topics such as upper-layer connection preservation and mobile network services are covered in section 4.
This section is broken down into four main parts. In order for a host to configure and manage itself, it must discover its neighbors and routing information. This neighbor discovery process is discussed in section 3.1. The primary steps of host configuration are outlined in section 3.2. In some environments, it is desirable for aspects of host configuration to be managed by a central authority, such as for temporary dial-in network service providers. This topic is covered in section 3.3. Finally, section 3.4 discusses address leasing and its relevance to network configuration and address renumbering.
Nodes use neighbor discovery to determine the link-layer addresses of neighbors known to reside on attached links and to quickly purge cached values that become invalid. Hosts also use neighbor discovery to find neighboring routers that are willing to forward packets on their behalf. Finally, nodes use neighbor discovery to actively keep track of which neighbors are reachable and which are not, and to detect changes in link-layer addresses.
The draft specification for neighbor discovery [7] describes procedures to detect and respond to a large set of network conditions. Examples include route discovery, subnet prefix discovery, address autoconfiguration, duplicate address detection, and more. Neighbor discovery allows nodes to be aware of their network state, and automatically change configurations should the need arise.
Unfortunately, the neighbor discovery protocol is extensive and a complete presentation of the protocol is beyond the scope of this report. However, it is important to note the protocol serves a critical and innovative part of the IPv6 robustness and configuration mechanism. The use of neighbor discovery is implied in subsequent sections and is used both during initial node configuration and during regular network operations.
When a host becomes present on an IPv6 network, it has the ability to perform an autoconfiguration process of its network interfaces. The autoconfiguration process includes creating a link-local address and verifying its uniqueness on the link, determining what information should be autoconfigured (addresses, other information, or both), and in the case of addresses, whether they should be obtained through the stateless mechanism (described below), the stateful mechanism (described in section 3.3), or both. The stateless autoconfiguration process is defined in [10].
Stateless autoconfiguration requires no manual configuration of hosts, minimal (if any) configuration of routers, and no additional servers. The mechanism allows a host to generate its own addresses using a combination of locally available information and information advertised by routers. Routers advertise prefixes that identify the subnet(s) associated with a link, while hosts generate an interface identifier that uniquely identifies an interface on a subnet. An address is formed by combining the two. In the absence of routers, a host can only generate link-local addresses. However, link-local addresses are sufficient for allowing communication among hosts attached to the same link.
To insure all configured addresses are likely to be unique on a given link, hosts run a duplicate address detection algorithm on addresses before assigning them to an interface. The duplicate address detection algorithm is performed on all addresses, independent of whether they are obtained via stateless or stateful autoconfiguration.
The stateless autoconfiguration process can be broken down into six general steps as outlined below:
Step 1: Discover the interface identifier. Network interfaces often have unique identifiers assigned to them by the manufacturer. Ethernet interfaces, for example, use the MAC sublayer address assigned to the Ethernet card.
Step 2: Append the well-known link-local prefix [5] to the interface identifier to derive a tentative link-local address. The link-local prefix is a special-purpose multicast prefix used during autoconfiguration and link-local communication; this enables an otherwise unconfigured device to communicate with other nodes on the network despite not having a site-local or global valid IP address for the interface.
Step 3: Insure the tentative link-local address is unique. The node sends a neighbor solicitation message containing the tentative address. If another node is already using the address, a neighbor advertisement message will be returned; otherwise, the address is presumed to be unique. Neighbor solicitation and neighbor advertisement messages are implemented as packet header extensions.
Step 4: Assign the link-local address to the interface. At this point, the node has IP-layer connectivity with neighboring nodes.
Step 5: Send out a router solicitation multicast message to all routers. This prompts the router(s) to respond with configuration information for the node. If no routers are present, stateful autoconfiguration (section 3.3) is invoked.
Step 6: Receive a router advertisement message with configuration instructions. The router advertisement message will instruct the node to use either stateless or stateful autoconfiguration. If stateless configuration is used, the router advertisement will include information used to generate site-local and global IP addresses. If stateful configuration is used, node configuration will continue as outlined in section 3.3.
The stateless autoconfiguration process applies only to hosts and not routers. Since host autoconfiguration uses information advertised by routers, routers will need to be configured by some other means. However, it is expected that routers will generate link-local addresses. In addition, routers are expected to successfully pass the duplicate address detection procedure on all addresses prior to assigning them to an interface.
From a purely robustness point of view, the stateless autoconfiguration process appears to have a potential weaknesses. The problem revolves around the transmission of neighbor solicitation messages during duplicate address detection. The internet draft [10] specifies that DupAddrDetectTransmits neighbor solicitation messages (DupAddrDetectTransmits = 1 by default) should be sent, each separated by RetransTimer milliseconds. Values for DupAddrDetectTransmits and RetransTimer are to be given values appropriate for the link medium. If no neighbor advertisement messages are returned, the address is presumed to be unique. The draft also specifies invalid neighbor solicitation messages (i.e. messages which are found to be corrupted) should be silently ignored. This sets up the potential for neighbor solicitation messages to be corrupted, and subsequently ignored, resulting in the erroneous assumption that the address is unique. Naturally, on mediums which have very low bit error rates, the chances of failure are small. However, the specified default value for DupAddrDetectTransmits is 1; this seems unnecessarily fragile except for technologies which, by design, already support unique interface identification values (e.g. Ethernet MAC addresses).
The dynamic host configuration protocol (DHCP) is the stateful counterpart to stateless autoconfiguration (section 3.2). In the stateful autoconfiguration model, hosts obtain interface addresses and/or configuration information and parameters from a server. DHCP servers maintain a database that keeps track of which addresses have been assigned to which hosts. The stateful autoconfiguration protocol allows hosts to obtain addresses, other configuration information, or both from a server. DHCP is specified in [2], [9], [6].
DHCP uses a client-server model; designated DHCP servers automatically allocate network addresses and deliver configuration parameters to dynamically configurable clients. DHCP uses request and reply messages to support a client/server processing model whereby both the client and server are assured that requested configuration parameters have been received and accepted by the client. This operation works with and complements the stateless autoconfiguration procedure discussed in section 3.2. The general steps in the stateful configuration procedure are summarized below.
Step 1: The client sends a multicast DHCP solicit message from the interface it wishes to configure. The client then awaits a DHCP advertise message.
Step 2: A DHCP server responds with a unicast DHCP advertise message containing the IP address of a DHCP server.
Step 3: DHCP transactions are initiated by the client with a unicast DHCP request message. The server will respond with a DHCP reply message, containing configuration information. After this point, the node should be fully configured and operational.
Step 4a: Should the DHCP server, at some point in the future, become reconfigured or otherwise obtain new information relevant to the client, it may send a DHCP reconfigure message. The client, upon reception of the message, is expected to re-initiate a DHCP request / reply transaction as in step 3.
Step 4b: Should the client, at some point in the future, no longer need addresses and/or resources allocated through the DHCP mechanism, the client may send a DHCP release message to the server. This message instructs the server to release the specified addresses and resources. The server will consequently recycle the addresses and resources, making them available for other clients to use.
All data packets in the DHCP transaction are presumed to have been received without errors. To provide a method of recovery if either the client or server does not receive its messages, the client retransmits each DHCP request message until it elicits the corresponding DHCP reply, or until it can be reasonably certain it does not want a response (i.e., it may abort the transaction). Timeout and retransmission guidelines are specified in [2]. The draft specification also details various exception conditions, and the proper ways to respond to them.
The draft DHCP specification also allows for multiple servers to operate on a single network [9], [6]. This provides DHCP server redundancy in the event of a server failure (called failover). DHCP failover procedures specify how to guarantee reliable delivery of changes from a primary DHCP server to a secondary server. This is required to synchronize the secondary’s address lease data (see section 3.4) with that of the primary. The protocol further specifies a mechanism for determining the state (operational or not) of the primary server. The secondary will be able to automatically service DHCP requests upon failover. When the primary server becomes available again, the secondary will convey any changes that occurred since the time of failover back to the primary prior to the primary becoming operational.
It is interesting to note the stateful autoconfiguration protocol (DHCP) appears significantly more robust than the stateless autoconfiguration protocol. DHCP contains more extensive timeout and retransmission guidelines which will compensate for corrupted or dropped packets. DHCP also includes extensive exception case guidelines for unusual circumstances (e.g. DHCP server reboots or becomes unavailable during a DHCP request / reply transaction). Finally, DHCP server failure can be managed through the use of redundant servers. Unfortunately, DHCP depends upon the stateless autoconfiguration process to initially obtain a valid link-local IP address before DHCP transactions can occur. Therefore, for new nodes on the network, DHCP is only as robust as its stateless autoconfiguration counterpart.
IPv6 addresses are leased to an interface for a fixed (possibly infinite) length of time. Each address has an associated lifetime that indicates how long the address is bound to an interface. When the lifetime expires, the binding (and address) become invalid and the address may be reassigned to another interface elsewhere in the Internet.
To handle the expiration of address bindings gracefully, an address goes through two distinct phases while assigned to an interface. Initially, an address is preferred, meaning that its use in arbitrary communication is unrestricted. Later, an address becomes deprecated in anticipation that its current interface binding will become invalid. While in a deprecated state, the use of an address is discouraged, but not strictly forbidden. New communications are supposed to use a preferred address when possible. A deprecated address is only used by applications that have already been using it and would have difficulty switching to another address without a service disruption.
Dividing valid addresses into preferred and deprecated categories provides a way of indicating to upper layers that a valid address may become invalid shortly and that future communications using the address may fail.
Routers periodically broadcast unsolicited router advertisement messages. This advertisement contains the same host configuration information as provided in response to a router solicitation as described in section 3.2. Newer information provided in router advertisement messages takes precedence over older information cached by a host. Therefore, by combining router advertisement messages and address leasing functionality, an entire subnetwork can be renumbered automatically over a period of time. Naturally, the change-over period cannot occur too quickly or existing network connections will be lost. However, if the change-over period exceeds the expected duration of most connections, connection disruptions will be minimized.
The address leasing mechanism is recursive for domains. As such, it is extremely useful in providing a mechanism for management and configuration of entire subnetworks. The critical phase in network renumbering, however, is when addresses become depreciated. It is expected when the primary address for an interface becomes depreciated, it is replaced by a new preferred address. However, the enforcement of a lifetime for the deprecated address requires knowledge of expected connection lifetimes. Since such knowledge is not currently available, there exists the very real possibility that, during address renumbering, some existing connections will be lost.
IPv6 introduces significant support for hosts which change their network addresses and point of attachment to the network. The automatic configuration of new nodes is discussed in section 3. Stateless and stateful autoconfiguration procedures do not, however, preserve pre-existing connections to the node, nor even maintain a single network identity for the node. This section discusses how IPv6 addresses these issues.
This section is broken down into three main sections. The concept of an IP tunnel is presented in section 4.1; this concept is integral to mobility support. Node mobility issues and specifications are discussed in section 4.2. Finally, special routing considerations for mobile nodes are discussed in section 4.3.
IPv6 tunneling is a technique for establishing a virtual link between two IPv6 nodes for transmitting IPv6 packets as payloads of other IPv6 packets (see figure Figure 4.1). From the point of view of the two nodes, this virtual link, called an IPv6 tunnel, appears as a point to point link on which IPv6 acts like a link-layer protocol.
The two IPv6 nodes at each end of a tunnel play specific roles. One node encapsulates original packets received from other nodes or from itself and forwards the resulting tunnel packets through the tunnel. The other node unpacks the received tunnel packets and forwards the resulting original packets towards their destinations, or possibly to itself. The encapsulating node is called the tunnel entry-point node, and it is the source of the tunnel packets. The unpacking node is called the tunnel exit-point node, and is the destination of tunnel packets.
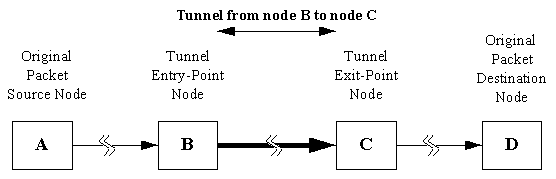
Figure 4.1: Illustration of an IPv6 tunnel [3].
Bi-directional tunneling is achieved by merging two unidirectional tunnels formed in opposite directions, the entry-point node of one tunnel is the exit-point node of the other tunnel (see Figure 4.2).
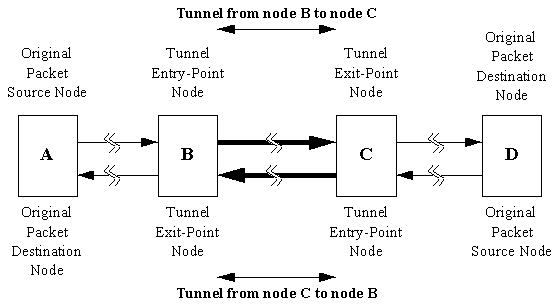
Figure 4.2: Illustration of bi-directional tunneling [3].
Packet encapsulation consists of adding an IPv6 header to the original packet and, optionally, a set of IPv6 extension headers which are collectively called tunnel headers. The encapsulation takes place in a tunnel entry-point node and is the result of an original packet being forwarded onto the virtual link represented by the tunnel.
During encapsulation, the source field of the tunnel header is filled with the tunnel entry-point node address, and the destination field with the tunnel exit-point node address. Subsequently, the tunnel packet resulting from encapsulation is sent towards the tunnel exit-point node. Intermediate nodes in the tunnel path process the tunnel packet according to regular IPv6 protocol conventions.
The tunnel entry-point node, which encapsulates the tunnel packets, and the source node, which sends the original packets, can be the same node.
Upon receiving a tunnel packet, the exit-point node processes, then strips the tunnel header from the tunnel packet. The unpacked packet is then processed according to regular IPv6 convention.
The tunnel exit-point node, which unpacks the tunnel packets, and the destination node, which receives the resulting original packets, can be the same node. However, the source and destination node cannot be the same node or else an infinite processing loop may occur.
When a node moves from one link to another, the node must usually inherit the subnet prefix of the current link (called the point of attachment). This results in a change to the node’s global IP address. Consequently, since most upper-layer protocols cannot accommodate changes to IP addresses, pre-existing connections are lost.
Mobile IPv6 allows a mobile node to change its point of attachment without changing the mobile node’s IP address. This has the desirable effect of preserving pre-existing connections with other nodes on the network. In order to accomplish this, the cooperation of a series of routers and hosts is required. The following sections discusses various aspects of mobility support in IPv6.
Every mobile node needs a home link. Normally, this is the link the mobile host resides on when it is "at home" (i.e. not mobile). A mobile node is always addressable by its home address, an IP address assigned to the mobile node within its home subnet prefix on its home link. Packets may be routed to the mobile node using this address regardless of the mobile node’s current point of attachment to the network, and the mobile node may continue to communicate with other nodes (stationary or mobile) after moving to a new link. The movement of a mobile node away from its home link is thus transparent to higher-layer protocols and applications.
When a mobile node is attached to some foreign link away from home, it is also addressable by one or more care-of addresses, in addition to its home address. A care-of address is an IP address associated with a mobile node while visiting a particular foreign link. The subnet prefix of a mobile node’s care-of address is the subnet prefix on the foreign link being visited by the mobile node; if the mobile node is connected to a foreign link while using the care-of address, packets addressed to the care-of address will be routed to the mobile node at its location away from home. The association between a mobile node’s home address and care-of address is known as a binding for the mobile node. A mobile node typically acquires its care-of address through stateless or stateful address autoconfiguration as described in section 3.
While away from home, the mobile node registers its care-of address with a router on its home link, requesting this router to function as the home agent for the mobile node. This binding registration is accomplished by the mobile node sending a binding update message to the home agent; the home agent replies with a binding acknowledgment message sent to the care-of address. The mobile node’s home agent thereafter intercepts any IPv6 packets addressed to the mobile node’s home address on the home link, and tunnels each intercepted packet to the mobile node’s care-of address. The tunnel is formed and managed as described in section 4.1. It is important to note a reverse tunnel is not necessarily required as packets sent from the mobile node may be generated and routed as normal. Figure 4.3 illustrates the relationships and packet flow between a correspondent and mobile node communicating through a home agent.
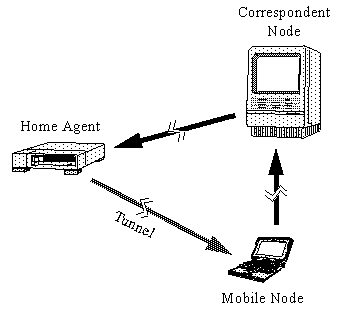
Figure 4.3: Illustration of a mobile and correspondent node communicating through a home agent.
Note binding updates, binding acknowledgments, and binding requests are implemented as IPv6 header extensions. As such, they may occupy their own packet, or may piggy-back payload-carrying packets such as TCP or UDP.
It is possible that while a mobile node is away from home, some nodes on its home link may be reconfigured, such that the router previously operating as the mobile node’s home agent is replaced by a different router. In this case the mobile node may not know the IP address of its own home agent. Mobile IPv6 provides a mechanism, known as dynamic home agent address discovery, that allows a mobile node to dynamically discover the IP address of a home agent on its home link. The mobile node sends a binding update message to the home agent’s anycast address for its home subnet prefix. The message reaches one of the (possibly many) routers on its home link currently operating as a home agent. This home agent likely rejects the mobile node’s binding update, but returns in the resulting binding acknowledgment a list of available home agents on the home link. This list is maintained by each home agent on the home link through use of each other’s periodic unsolicited multicast router advertisement messages.
Many routers implement security policies such as "ingress filtering" that do not allow forwarding of packets containing topologically incorrect source addresses. Consequently, while away from its home link, a mobile node will typically use its care-of address as the source address in packets it originates. By using the care-of address as the IPv6 header source address, the packet will be able to pass normally through such routers. However, the mobile node will also include its home address in a header extension. By also including the home address, the correspondent node receiving the packet can make use of the home address transparently above the Mobile IPv6 support layer.
The base Mobile IPv6 protocol allows any mobile node to move about, changing its point of attachment to the network, while continuing to be identified by its home IP address. Correspondent nodes send packets to a mobile node at its home address in the same way as with any other destination. This scheme allows transparent interoperation between mobile nodes and their correspondent nodes, but forces all packets for a mobile node to be routed through its home agent. Thus, packets to the mobile node are often routed along paths that are significantly longer than optimal. This indirect routing delays the delivery of packets to the mobile node, and places an unnecessary burden on the networks and routers along their paths through the network.
Route optimization provides a means for correspondent nodes to cache the binding of a mobile node and to then tunnel their own packets directly to the care-of address indicated by the binding, bypassing the mobile node’s home agent. Provisions are also made to allow packets in flight when a mobile node moves, and packets sent based on out-of-date cached bindings, to be forwarded directly to the mobile node’s new care-of address. Route optimization is described in [8].
Mobile route optimization is broken down into two sections. Section 4.3.1 discusses the creation and updating of binding caches in correspondent nodes. Section 4.3.2 deals with managing smooth handoffs between foreign agents.
In the absence of any binding cache entry, packets sent from a correspondent to a mobile node will be routed to the mobile node’s home address in the same way as any other packet. From there, the packets are tunneled to the mobile node’s current care-of address by the mobile node’s home agent.
Route optimization provides a means for any node to acquire and maintain a binding cache containing the care-of address of one or more mobile nodes. When sending a packet to a mobile node, if the sender has a binding cache entry for the destination mobile node, it may tunnel the packet directly to the care-of address indicated by the cached mobility binding.
When a mobile node’s home agent intercepts a packet from a correspondent node, the home agent may deduce the original source of the packet has no binding cache entry for the destination mobile node. The home agent then sends a binding update message to the correspondent node, informing it of the mobile node’s current mobility binding. No acknowledgment for such a binding update message is required since any future packets from the correspondent intercepted by the home agent will cause a retransmission of the binding update message. In this manner, the correspondent node is provided with the binding information for the mobile node.
When binding information is provided to a correspondent in a binding update message, the binding is provided with an expiry date. If no subsequent binding update messages are sent to a correspondent and the binding expires, it is deleted from the cache and no longer used. At this point, the correspondent reverts back to sending packets to the mobile node’s home address.
Foreign agents are nodes on the foreign link which operate in conjunction with and on behalf of a mobile node to facilitate mobile IP operations. When a mobile node moves and registers with a new foreign agent, packets in flight that have already been tunneled to the old care-of address (or which were sent based on an invalid binding cache) will be dropped by default. This requires upper-layer protocols to detect and retransmit the lost packets, resulting in sub-optimal operation.
Route optimization provides a means for the mobile node’s previous foreign agent to be notified of the mobile node’s new mobility binding, allowing packets in flight to the previous foreign agent to be intercepted and forwarded to the new care-of address.
As part of the registration procedure, when changing the point of attachment, a mobile node requests its new foreign agent to attempt to notify the previous foreign agent on its behalf. The new foreign agent sends a binding update message to the old foreign agent which, in turn, should thereafter forward packets to the new care-of address.
Using the methods described in this section, a mobile host moving rapidly between points of attachments will tend to grow a long "previous foreign agent" tail. However, because each binding cache entry is marked with an expiry date, the bindings will automatically disappear. After the previous foreign agent cache has expired, it would be unusual for the previous foreign agent to receive any more packets for the mobile host. Normally, correspondent caches (which also contain expiry dates) will expire, in the limit, at the same time as a previous foreign agent’s cache. Therefore, at the same time a previous foreign agent’s cache expires, the correspondent’s cache will (or already has) expire, forcing the correspondent to revert to sending packets to the mobile host’s home address. The only exception to this is in the event packets with old bindings are delayed in transit and arrive after the previous foreign agent’s binding has expired. In this case, the packets will be dropped.
This report analyzes the Internet Protocol version 6 (IPv6) for its configuration and robustness attributes. Specifically, on-the-fly configuration and fault tolerance is emphasized.
The IPv6 architecture and address structure casts a balance between routing data abstraction and allowing practical network topology. Furthermore, the architecture contains significant consideration for future enhancements and additions.
Autoconfiguration of hosts in IPv6 almost completely eliminates the mundane task of manually configuring new nodes in a network. Through neighbor discovery and address leasing protocols, configured nodes maintain current information and address binding, and can even automatically assume new subnet prefix values if required. The autoconfiguration process depends on some potentially fragile assumptions. However, for the likely targeted network technologies, there should be few problems. Should the protocol be implemented on link mediums with high bit error rates and/or a high potential for duplicate link-layer identifiers, however, the protocol may need improvements before operating satisfactory.
Lastly, Mobile IPv6 frees mobile nodes from the bonds of static IP address restrictions. Mobile IPv6 combines tunnels and mobile protocols, permitting mobile nodes to maintain upper-layer connections despite changes to the point of attachment. Furthermore, route optimization for mobile IP ensures network and CPU resources are optimized by minimizing the packet path to a mobile node.
In general, the Internet Protocol version 6 is an enormous work in progress which, despite hundreds of active designers, thousands of active developers, and millions of expected future users, promises to work exceptionally well.
[1] "Internet Protocol," RFC 791, Information Sciences Institute, September 1981.
[2] J. Bound, C. Perkins, "Dynamic Host Configuration Protocol for IPv6," work in progress, Compaq Computer Corporation, Sun Microsystems, June 28 1998.
[3] A. Conta, S. Deering, "Generic Packet Tunneling in IPv6," work in progress, Lucent Technologies, Cisco Systems, January 1998.
[4] S. Deering, R. Hinden, "Internet Protocol, Version 6 (IPv6) Specification," work in progress, Cisco Systems, Ipsilon Networks, November 21 1997.
[5] R. Hinden, S. Deering, "IP Version 6 Addressing Architecture," RFC 1884, Ipsilon Networks, Xerox PARC, December, 1995.
[6] K. Kinnear, "DHCP Safe Failover Protocol," work in progress, American Internet Corporation, March 1998.
[7] Thomas Narten, Erik Nordmark, W. A. Simpson, "Neighbor Discovery for IP Version 6," work in progress, IBM, Sun Microsystems, Daydreamer, February 24 1998.
[8] Charles Perkins, David B. Johnson, "Route Optimization in Mobile IP," work in progress, Sun Microsystems, Carnegie Mellon University, November 20 1997.
[9] Greg Rabil, Mike Dooley, Arun Kapur, Ralph Droms, "DHCP Failover Protocol," work in progress, Quadritek Systems, Q. S., Q. S., Bucknell University, February 1998
[10] Susan Thomson, Thomas Narten, "IPv6 Stateless Address Autoconfiguration," work in progress, Bellcore, IBM, February 17, 1998.
address
An IPv6-layer identifier for an interface or a set of interfaces.
anycast address
An identifier for a set of interfaces (typically belonging to different nodes). A packet sent to an anycast address is delivered to one of the interfaces identified by that address.
autoconfiguration
The process by which a new or existing node on a network procures configuration information from itself and the network.
binding
A cached address maintained at a node. If a permanent host address is bound to a temporary care-of address, packets will be tunneled directly to the care-of address.
care-of address
The temporary IP address at which a mobile node can be reached while maintaining a foreign point of attachment on a foreign link.
deprecated address
An IP address which shall soon become invalid. New network connections are discouraged, though not forbidden, to connect to this address. See preferred address.
domain
A collection of one or more nodes and/or subnetworks which share a subnet prefix.
duplicate address detection
The process by which a node can insure its tentative link-layer address is unique.
entry-point
The start of a tunnel where packets are encapsulated.
exit-point
The end of a tunnel where encapsulated packets are unpacked and forwarded as normal.
foreign link
A remote link which is serving as the point of attachment for a mobile node.
foreign agent
A node on the foreign link which acts on behalf of a mobile node to help the mobile node acquire and/or maintain network connectivity and pre-existing connections.
header
See packet header.
header extension
Optional extension fields added to a packet header to include special messaging or control information with a packet.
home address
The permanent IP address at which a mobile node can always be reached.
home agent
The router on the home link which, on behalf of a mobile node, intercepts packets intended for the node and tunnels them directly to the mobile node at its care-of address.
home link
The link which a mobile node originates from and/or receives services from. From a network point of view, a mobile node will appear as though it is located local to its home link. It’s physical point of attachment may be anywhere on the network, however.
host
Any node that participates on the network but does not act as a router. Note a node may act as a host and a router, depending on what operation it is performing.
interface
A node’s attachment to a link.
link
A communication facility or medium over which nodes can communicate at the link layer, i.e., the layer immediately below IPv6. Examples are Ethernets, PPP links, X.25, Frame Relay, ATM, and internet (or higher) layer "tunnels".
link-layer address
An address having link-only scope that can be used to reach neighboring nodes attached to the same link. All interfaces have a link-local unicast address.
link-local address
See link-layer address
mobile host
A host which changes its point of attachment from time to time or, in the simplest case, does not physically reside on its home link.
multicast address
An identifier for a set of interfaces (typically belonging to different nodes). A packet sent to a multicast address is delivered to all interfaces identified by that address.
neighbors
Nodes attached to the same link.
node
A device that implements IPv6 and maintains a presence on the network.
packet
A self-contained collection of information carrying data through the network. Data is transmitted through the network in self-contained units called packets.
packet header
The administrative portion of a packet which the network IP layer uses to perform routing, encapsulation, unpacking, etc.
payload
The portion of a packet which contains the data intended to be communicated between nodes.
point of attachment
The point, or link, on the network (from a network topology point of view) to which a node attaches itself. Normally, a node must base its subnet prefix, and thus part of its IP address, on the link it is attached to.
preferred address
A valid IP address which can be used to initiate connections with other nodes on the network. See deprecated address.
provider
A domain which shares its resources with other sub-domains, thus granting the sub-domains access to the network. See subscriber.
router
A node that forwards IPv6 packets not explicitly addressed to itself.
routing
The act of recursively forwarding a packet from node to node until it reaches its destination.
server
A network node offering some form of network services. For example, a DHCP server maintains and offers DHCP information and services to other nodes on the network.
stateless
Stateless autoconfiguration is a process by which a new host can acquire network services with, or without intervention of other nodes on the network.
stateful
Stateful autoconfiguration is a process by which a new host acquires configuration information from a central authority located on the network.
subnet prefix
The most significant bits of an IP address which are shared by all nodes and subnetworks attached to a given link.
subscriber
A domain which utilizes other domain’s resources to obtain network connectivity. For example, a single node on a university campus network is a subscriber of the university domain; it depends on the university’s network and connectivity to provide it with network services. See provider.
tunnel
A special link whereby encapsulated packets are transmitted over the network in a transparent manner. The tunnel appears as a link-layer point to point connection. Tunnels are used by Mobile IPv6 to forward packets from a home agent to a mobile node.
tunnel headers
IP header extensions unique to encapsulated packets.
tunneling
The process of creating, maintaining, and using a tunnel.
unicast address
An identifier for a single interface. A packet sent to a unicast address is delivered to the interface identified by that address.
upper-layer
A protocol layer immediately above IPv6. Examples are transport protocols such as TCP and UDP, control protocols such as ICMP, routing protocols, and internet or lower-layer protocols being "tunneled" over (i.e., encapsulated in) IPv6 such as IPX, AppleTalk, or IPv6 itself.