
by
BRYAN CAMERON LESIUK
B. Eng., University of Victoria, 1994
A Thesis Submitted in Partial Fulfillment of the
Requirement for the Degree of
MASTERS OF APPLIED SCIENCE
in the
Department of Mechanical Engineering
Examiners:
Dr. G. McLean, Supervisor (Dept. of Mechanical Engineering)
Dr. J. Provan, Department Member (Dept. of Mechanical Engineering)
Dr. M. Miller, Outside Member (Dept. of Computer Science)
Dr. Kin Li, External Examiner (Dept. of Electrical Engineering)
© Bryan Cameron Lesiuk, 2000-2001
This thesis is hereby released into the public domain.
NOTE: This document is not necessarily the same as the thesis I defended. Due to translations errors, this copy and the original may differ in some regards. Official copies are available at the University of Victoria Library and the Canadian national archives.
Preamble:
This document was originally written in Frame Maker 4.0 and later translated into HTML using the free Perl program "MifMucker". I used screen captures to manually transfer the graphics.
Click here to return to my home page.
Measurement networks are data acquisition networks built using microcontrollers and have a variety of problems involving their construction, operation, and maintenance. This thesis investigates the feasibility and ramifications of incorporating routing protocols into measurement networks to mitigate or eliminate these problems. Existing routing protocols are analyzed for their ideas and applicability to measurement networks. Focus is given to ad hoc routing protocols which combine the simplicity and characteristics desired for measurement networks. The ramifications of implementing ad hoc routing protocols in measurement networks, such as the use of redundancy, are investigated. One ad hoc routing protocol is selected and implemented in a simulated measurement network environment to show it is not only possible to accomplish the goals of this thesis, but also quite practical. This thesis concludes measurement networks incorporating ad hoc routing protocols are possible, practical, and enjoy numerous enhancements above regular measurement networks.
Examiners:
Dr. G. McLean, Supervisor (Dept. of Mechanical Engineering)
Dr. J. Provan, Department Member (Dept. of Mechanical Engineering)
Dr. M. Miller, Outside Member (Dept. of Computer Science)
Dr. Kin Li, External Examiner (Dept. of Electrical Engineering)
Figure 1-1 : Simple network with three nodes
Figure 1-2 : Network with eight nodes connected by four separate links
Figure 1-3 : Ad hoc network of three wireless mobile nodes
Figure 1-4 : Ad hoc network with four wireless nodes
Figure 2-1 : Example of a hierarchical IP network structure.
Figure 2-2 : Example of an IP network with loops.
Figure 2-3 : Illustration of a CDPD network.
Figure 2-4 : Illustration of multiplexed packets (cells) in an ATM transmission.
Figure 2-5 : Illustration of virtual channels between ATM nodes.
Figure 2-6 : Illustration of circuit routing inside an ATM node.
Figure 2-7 : Hierarchical network view of an ATM network.
Figure 2-8 : ATM network configuration as seen from node X.B.2.
Figure 2-9 : Illustration of a mobile ATM node being handed off.
Figure 3-1 : An example of the routing procedure in DSDV.
Figure 3-2 : A node receiving three update packets.
Figure 3-3 : Generation of an ordered graph in TORA.
Figure 3-4 : TORA protocol reaction to node mobility.
Figure 3-5 : A packet being source routed from node 9 to node 5.
Figure 3-6 : Physical and virtual subnets in an ad hoc network.
Figure 3-7 : Multi-point relay versus conventional broadcasting.
Figure 4-1 : A network of two nodes connected by a single link.
Figure 4-2 : A network of two nodes connected by two links.
Figure 4-3 : Two-node network with link failure PDF.
Figure 4-4 : Two-node, two-link network and a graph of the single link PDF and the resulting network partitioning PDF.
Figure 4-5 : Example of a sampled failure distribution Dfailure.
Figure 4-6 : Network with two nodes connected by two links.
Figure 4-7 : Derivation of Dpartitioned from two independent Dfailure distributions.
Figure 4-8 : Sample calculation of Dpartitioned for t = 2 for a three-node three-link network.
Figure 4-9 : Failure PDFs for four-node networks.
Figure 4-10 : Plots of Dpartitioned for a two-node network with one, five, 10 and 20 links.
Figure 4-11 : Plots of Dpartitioned and log(Dpartitioned) for a four-node network.
Figure 4-12 : Plots of Dpartitioned and log(Dpartitioned) for a four-node network with an irregular Dlink_failure.
Figure 4-13 : Done_or_more_link_failure and Dpartitioned for a four-node four-link network.
Figure 4-14 : Nodes connected by cable running through garage door.
Figure 4-15 : Three failure modes and resulting Dpartitioned.
Figure 4-16 : Network with a single common link.
Figure 4-17 : Network topology with potential for congestion.
Figure 4-18 : Network tree topology with potential for congestion.
Figure 4-19 : Extended tree topology with potential for congestion.
Figure 4-20 : Network with a single common link.
Figure 4-21 : Tree topology with potential for latency.
Figure 5-1 : Simulator segmentation as compared to the OSI 7-Layer model.
Figure 5-2 : Packet flow through the network layers.
Figure 5-3 : Format of the four DSR packet types.
Figure 5-4 : DSR route discovery, route reply, and data transmission.
Figure 5-5 : Return of a route error packet in response to a link failure.
Figure 5-6 : Illustration of every packet is broadcast algorithm.
Figure 5-7 : MAC address source routing.
Figure 5-8 : Network topologies used for simulation tests.
Figure 5-9 : Convergence distribution for start-up tests using networks A, C and E.
Figure 5-10 : Convergence distribution for start-up tests using networks B, D and F.
Figure 5-11 : Convergence distribution for link failure tests using networks A, C and E.
Figure 5-12 : Convergence distribution for new link/node tests using networks A, C and E.
Figure 5-13 : Convergence distribution for new link/node tests using networks B, D and F.
This thesis would not have been possible without the unquestioning friendship and support from Dr. Michael Miller, Dr. Ged McLean, Jason Szabo, Glen Rutledge, and my family and friends. My heartfelt thanks and appreciation goes to all of you.
Measurement networks are networks of simple computing devices designed to monitor and report the status of a test subject. For example, a measurement network may be used to monitor the stress on a boat steering mechanism, measure the force exerted by a cyclist on their bicycle pedal, or monitor environmental conditions within a room.
Measurement networks, as they exist today, have problems involving their construction, operation, and maintenance. This thesis and the accompanying research were instigated to find ways these problems could be mitigated or eliminated. It was determined implementing ad hoc routing protocols in measurement networks would go a long way towards achieving this goal. This thesis discusses the feasibility and ramifications of implementing ad hoc routing protocols in measurement networks.
The following sections introduce concepts which are essential to an understanding of this thesis. Section 1.1 presents an introduction to multi-hop networks and routing protocols. This thesis deals mainly with routing protocols for ad hoc networks. Therefore, Section 1.2 introduces ad hoc networks and discusses how these differ from conventional networks. Section 1.3 presents a rough definition of measurement networks and their application. Finally, Section 1.4 discusses the scope and assumptions made by this thesis.
A network is a collection of two or more computing devices connected by a communication medium. Figure 1-1 shows a simple network with three computing devices. When a computing device wishes to send information to another device, it may do so by transmitting the information along a shared communication medium.
In this thesis, any computing device actively participating in a network is called a node. Nodes are connected by a communication medium or link. Nodes exchange information over links in discrete blocks called packets.
In Figure 1-1, any node can communicate with any other node along the single link. In this case, no special steps are needed for any two nodes in the network to exchange information (assuming issues such as medium contention are resolved by the medium implementation). If, however, nodes in a network do not share a common link, this no longer holds true. Figure 1-2 shows a network where different nodes share different links.
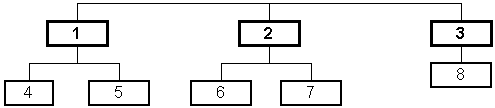
For example, in Figure 1-2, in order for node 1 to send a packet to node 8, the packet must first be sent to node 3. Node 3 must subsequently be willing and able to forward the packet on to node 8. The links and nodes a packet traverses along its journey from source to destination is called the packet's path.
Whenever a packet is transmitted from one node to another, it is said to have made a hop. In the above example, a packet sent from node 1 to node 3 requires one hop, whereas a packet sent from node 1 to node 8 requires two hops (one hop from node 1 to node 3, and a second hop from node 3 to node 8).
In the above example, the various nodes along the packet's path from node 1 to node 8 must cooperate in order to make the information exchange successful. As the packet passes through each node, the node must decide where the packet should be sent next. The task of finding a path from a sender to a desired destination is called routing. The task of routing is performed through the use of routing protocols, standard procedures designed to facilitate and perform routing.
Routing in conventional network technologies, such as the Internet Protocol (IP) [10] [26] or Asynchronous Transfer Mode (ATM) [29], is simplified by designing the topology in a predictable (usually hierarchical) manner. The topology of a network is the way in which nodes are connected to each other. In hierarchical networks, the routing protocol can take advantage of the topology structure, resulting in a simplified routing algorithm.
When the topology of a network changes, routing protocols can experience problems such as node unavailability and routing loops. These problems may persist until the routing protocol compensates for the topology change and returns to a stable state. The process of returning to a stable state after a topology change is called convergence. The time required for a routing protocol to converge is called its convergence time. Conventional networks tend to change infrequently, relaxing the burden on the routing protocol to respond to topology changes.
This thesis deals mainly with ad hoc routing protocols. It is useful to introduce ad hoc networks and describe how they are different from conventional networks. In this section, it is assumed the nodes are mobile and use wireless radio frequency (RF) transceivers as their network interface, although many of the same principles will apply to wire based networks.
An ad hoc network is a collection of nodes forming a temporary network [42]. The network operates without the centralized administration or support services available to conventional networks. Some form of routing protocol is necessary in these ad hoc networks since two hosts wishing to exchange packets may not be able to communicate directly.
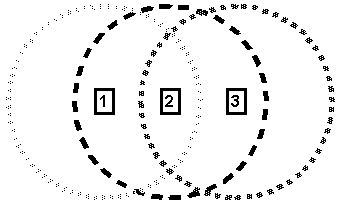
For example, Figure 1-3 illustrates an ad hoc network with three wireless mobile nodes. The range of each node's transceiver is indicated by a dashed circle around the node. Notice node 3 is not within the range of node 1's transceiver and vice versa. If node 1 and node 3 wish to exchange packets, they must enlist the services of node 2 to forward packets on their behalf.
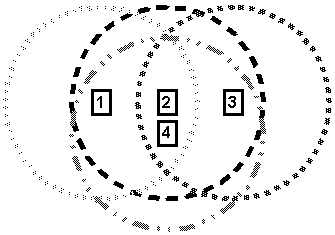
The situation in Figure 1-3 becomes more complicated with the addition more nodes. The addition of just one node, as illustrated in Figure 1-4, results in multiple paths existing between nodes 1 and 3; packets may travel the path 1 - 2 - 3, 1 - 4 - 3, or even 1 - 4 - 2 - 3. An ad hoc routing protocol must be able to deal with multiple paths existing between any two nodes.
Ad hoc networks must deal with frequent changes in topology. By their very nature, mobile nodes tend to "wander around", changing their network location and link status on a regular basis. New nodes may unexpectedly join the network or existing nodes may leave or be turned off. Ad hoc routing protocols must minimize the time required to converge after these topology changes.
Ad hoc routing protocols fill the space between two network extremes. At one extreme, the network topology is changing so rapidly the only feasible routing mechanism is for every packet to be flooded throughout the network. At the other extreme, the network topology is sufficiently permanent and static as to permit the use of conventional routing mechanisms such as those employed in the Internet. Ad hoc networks are networks which lack the support structure and permanency of traditional networks, yet change sufficiently slowly as to permit the use of a routing protocol to optimize transmission bandwidth.
In this thesis, ad hoc routing technology is being investigated for benefits other than the mobility factor. The characteristics of ad hoc routing protocols make them particularly attractive in measurement networks. Measurement networks and their characteristics are described further in Section 1.3. For more information on the characteristics of ad hoc networks, see [24].
This section describes measurement networks as defined within the scope of this thesis. Section 1.3.1 discusses the general characteristics of measurement networks. Sections 1.3.2 to 1.3.4 discuss the problems and limitations of measurement networks which this thesis hopes to mitigate or eliminate.
A measurement network typically consists of a series of simple computing devices connected by a communication medium. The purpose of a measurement network is to collect data from one or more sensors and relay this information over the communication medium to where it can be processed, presented, and/or recorded. By far the most common medium is a wire of some sort, but other mediums such as fiber optic cable or wireless radios may be used.
The distinction between measurement networks and regular networks is arguable. For the purposes of this thesis, a measurement network consists of simple computing devices connected by simple network technologies. The computing devices do not have clock rates in the GHz, huge memory, and the plethora of external devices regular "desktop" computers enjoy. These devices often have less than 200 bytes of RAM, clock rates of 40MHz or less, and have only two peripherals: a sensor, and a network interface. The network technologies employed use bit rates from between 104 to 106 bits per second, whereas technologies such as ethernet [1] and token ring [2] operate at 106 to 109 bits per second. Examples of simple computing devices include the 8051 [12], 68HC11 [11], and PIC [13] microcontrollers. Examples of simple network technologies include I2C [9], SPI [11], and CAN [4][5][6][7][8] architectures.
A measurement network also typically consists of a small number of nodes. Measurement networks are composed of less than 1000 nodes. In contrast, the Internet Protocol is designed to operate with millions of nodes. This puts very different demands on the routing protocols used in measurement networks versus the Internet, for example.
The "StressNet" system from iDAQ (Appendix 1:) serves as an excellent example of a measurement network. The network is powered by 8051-based microprocessors [3] and utilizes a single shared I2C [9] network to connect the nodes together. The 8051 microprocessors run at about 1-2 million instructions per second (MIPS). The I2C network operates at a rate up to 105 bits per second. The Stressnet network is capable of a maximum total sampling rate of 1000 Hz. At this rate, the network is operating at peak capacity and the 8051's have barely enough time to sample their sensor, perform some simple preconditioning on the raw data, and transmit the resulting information to a central location for logging.
The challenge of implementing any sort of networking layer within the confines of a measurement network such as StressNet is obviously formidable. For this thesis, the StressNet system will act as the model where real-world constraints are required. Please refer to Appendix 1: for a description of the StressNet system.
The construction of measurement networks can be quite cumbersome. Instrumenting a suspension bridge, for example, requires the measurement network be laid over long distances and under dangerous conditions. Under these circumstances, it is desirable to have configuration of the network as fast and automatic as possible; nobody wants to be left hanging under a bridge because their measurement network is not working properly. Instrumenting vehicles is also awkward and may require significant physical and electromagnetic protection of the instrumentation equipment. Once embedded, such a measurement network is difficult to access for maintenance of any sort. These sorts of applications make it difficult to setup, configure, and maintain measurement networks.
All network technologies have distance and device count limitations. CAN links, for example, operating at a nominal 106 bits per second cannot have a total network length exceeding approximately 30 meters [4]. Clearly a measurement network using a single CAN backbone will encounter technical difficulties instrumenting a large suspension bridge. However, if the network could automatically discover and use multiple links and pathways, multiple links could be laid end to end to span the bridge without problems.
Measurement networks are also used in laboratories. Research, by its very nature, is a path of discovery. One doesn't always know how to instrument a test specimen. Frequent changes to the measurement network are expected. Unfortunately, many measurement networks are difficult and time consuming to reconfigure or change. Alleviating this problem would save researchers valuable time and money.
Measurement networks are often embedded. This implies access to the network is limited. There are no "interfaces" to an embedded network, no way to "log in", setup routing tables, or test for link integrity. Without special equipment, maintaining a measurement network can be difficult or even impossible.
Maintenance in ad hoc routing networks will still likely require special equipment. However, repairs can be conducted on ad hoc networks in ways undreamt of in conventional networks. For example, if a link fails in a difficult to access location, a second link could be laid around the problem area without the removal of or concern for the failed link. Or, depending on the network topology, the failed link may not result in lost network connectivity and may be temporarily ignored altogether.
Most networking technologies today assume there exists a central support structure to maintain them. In the case of the Internet, for example, this support structure consists of people and equipment actively maintaining routing paths, domain name databases, and so forth. In an embedded network, a central support structure is obviously scaled down, but nonetheless may exist as a bus master, router (for multi-hop networks using conventional routing schemes), and so forth.
A central support node or nodes, using special hardware and software, is usually required to implement a central support structure. This introduces an added level of complexity and may result in added difficulties for system designers and measurement network users. The added complexity for system designers comes in the form of extra components to design and debug. At least two independent products, one for regular nodes, and one for the network server, need to be designed and manufactured. For users, the central support node may require configuration which, as discussed in Section 1.3.2, can be problematic.
Central authorities also introduce a vulnerability into the network; if the central authority fails, the entire network fails. Redundant central authorities may be utilized, but then there are synchronization problems (e.g.: who is the real authority and who is the backup) and added layers of complexity. In the extreme case, every node is also a central authority. However, this extreme case is essentially a form of ad hoc networking, and so we have come full circle.
The use of redundancy in computer networks is almost as old a concept as networks themselves. However, the ability to automatically detect and use redundant links is a relatively new ability in routing technologies. Common routing protocols such as the Routing Information Protocol (RIP) [43] need to be configured to "look for" redundant paths before they can be used. In a sense, these routing technologies need to know of the existence of redundant paths a priori. Ad hoc technologies on the other hand actively discover changes in link status and route accordingly.
Measurement networks have several attributes which make redundancy a particularly appealing characteristic. For example, many measurement networks are in mission-critical applications; a failure of the measurement network could have ramifications from the inconvenient to the catastrophic. As another example, many measurement networks are embedded and difficult to repair or replace. Redundancy allows these networks to continue to function until a convenient time or place can be found to enact repairs.
In order to bound the scope of this thesis, some assumptions were made.
The first assumption is important to mention early as it impacts the analysis in all subsequent sections. In this thesis, it is assumed all links in a network operate at equivalent transmission rates or throughput. This assumption is not strictly necessary. However, it simplifies the analysis and discussions of networks a great deal. Furthermore, this is not unreasonable to expect as many measurement networks are constructed of homogeneous link technologies.
In this thesis, it is assumed the total network traffic in any given network is sufficiently limited so as to avoid, but not eliminate, congestion. It is also assumed buffer overflows will be avoided so as to prevent the resulting packet loss. These two assumptions deal mainly with queueing and are discussed in more detail in sections 4.3 and 4.4.
The above notwithstanding, in this thesis, it is implicitly assumed packet delay and occasional packet loss will occur. For example, this thesis assumes occasional bit errors on the network links will cause packet corruption. Furthermore, it is assumed this is acceptable and will not lead to a catastrophic event. Because of this assumption, this thesis may not be applicable to control networks where if critical control messages are lost or delayed, ramifications in the physical world render unacceptable results. This thesis occasionally mentions the issues of packet loss, packet retransmission, and packet delay, but focus and priority is given to other topics.
In this thesis it is assumed all packets are small, consisting of 20 to 50 bytes in general. For example, the only information expected to be contained in the payload of a data measurement packet is the time the data was sampled and the data itself. Packet fragmentation, where a large packet is broken into multiple smaller packets for transmission, is not typically supported nor required in measurement networks and is therefore not investigated in this thesis.
In any investigations into routing protocols, it is useful to review the main routing protocols in use today. This provides the ground work for understanding ad hoc routing protocols in later sections.
The following sections present a brief description of the two most prevalent networking protocols, the Internet Protocol (IP) [26] [10] and Asynchronous Transfer Mode (ATM) [29]. Focus is given to the method of routing in these protocols. Of particular interest is the difficulty of configuration, the ability of the routing protocol to respond to network changes, and the overall complexity of the routing mechanism.
IP is a mature and well defined packet switched networking technology. Many technologies have been developed and implemented using IP or variations of IP.
In its simplest form, an IP network is arranged as a hierarchy as illustrated in Figure 2.1 [26] [10] [22]. Note each layer of the hierarchy has its own portion of the address space allocated to it; all nodes below a given network level share the same address prefix. If a source node wishes to send a packet to a destination node, but the two nodes are not directly connected by a link, the packet is transmitted to the next node closest to the destination for forwarding.
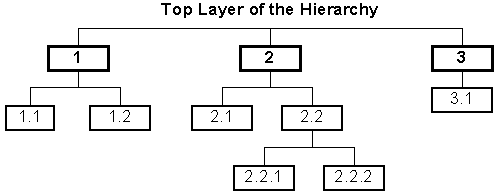
For example, in Figure 2.1, if node 2.2.1 sends a packet to node 3.1, the packet will travel to node 2.2, 2, 3, and finally to 3.1 respectively.
By organizing the IP network as a hierarchy of subnetworks, IP routing decisions are made relatively simple. Should any node in the network need to send a packet to another node, the routing algorithm can discover which node it should forward the packet to next merely by analyzing the destination network address.
A more interesting example of an IP network is illustrated in figure 2.2. In this case, the network has loops.
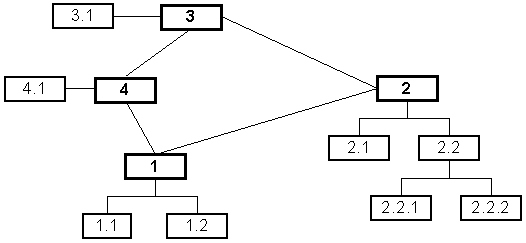
In order to decide where packets should be sent, IP networks utilize routing tables and routing algorithms. Programs such as RIP [43] maintain the routing tables and perform the routing operation. In Figure 2.2, node 1 can send packets to node 3 via either of nodes 2 or 4. Node 1 may, by default, send packets to node 3 via node 2. However, should the link between 1 and 2 be severely congested or fail altogether, node 1 may dynamically decide to send packets to node 3 via node 4.
In standard IP networks, each node in the network has a unique network address based on where in the network hierarchy the node resides. When nodes are added or removed from the network, or when links between nodes are created or destroyed, the routing tables and routing algorithms may have to be updated. A router normally accomplishes this by participating in distributed routing and reachability algorithms with other routers.
It should be noted loops in the network, as illustrated in Figure 2-2, break the hierarchical structure of the IP network. This is the reason non-trivial routing solutions such as RIP must be employed. Most IP networks conform to the hierarchical structure and do not require RIP to perform routing. Typically, in the Internet, only very large subnetworks and main backbone operators use dynamic routing algorithms.
When a new node is added to an IP network, it must be assigned a unique IP address. This address must reflect the node's position in the network hierarchy. Under most circumstances, this requires human intervention to configure the node. Once a new node has been assigned an IP address, traffic should be able to reach it without any problems; because of the hierarchical nature of IP networks, the IP address will tell other machines how to reach it.
There are provisions in some networks to provide IP addresses dynamically, such as for dial-in PPP and SLIP connection servers. These systems may appear to an end user to be self configuring. However, these systems have in fact been "pre-configured" with a pool of valid IP addresses which may be assigned to temporary nodes. Special software is used to manage the IP address pool and update routing tables. Under PPP or SLIP, when a temporary connection is terminated, the IP addresses assigned to the temporary node is recycled.
When a node is removed from an IP network, traffic is merely not routed to it anymore. If the node was the only way to reach other parts of the network, those parts are subsequently cut off as well. If there are alternate routes around the removed node, routing tables (using a protocol such as RIP) may be automatically updated, adapting to the new network topology. Unfortunately, RIP can be somewhat slow; until all of the routing tables have been updated, network connectivity may be denied. Naturally, where static routing tables exist, human intervention is required to manually change the tables.
It is fairly clear from this discussion generic IP networks require significant manual intervention to configure and maintain. Adding and removing nodes can be trivial or difficult, depending on the node's position and importance in the network. In some cases, where RIP is used, routing tables may be automatically updated when critical nodes or links are added or removed. Where RIP is not used, routing tables must be updated manually when links or routers are added or removed. F. Baker, in discussing IP routers in RFC 1812 [18], had the following to say:
| "In an ideal world, routers would be easy to configure, and perhaps even entirely self-configuring. However, practical experience in the real world suggests that this is an impossible goal, and that many attempts by vendors to make configuration easy actually cause customers more grief than they prevent." |
In the case of nomadic nodes, IP has virtually no support. A nomadic node is a node which changes its network location. In the simplest case, a nomadic node will appear to the network as a series of node additions and node removals regardless of the method of connection used (PPP, ethernet, etc.). When a nomadic node changes IP addresses as a result of a change in network location, all active connections to the node, such as a TCP connection, will be broken and need to be recreated.
Cellular Digital Packet Data (CDPD) is a digital packet-switched data network on the North American AMPS analog cellular system [53]. CDPD is based on existing data networking standards and on IPv4. The interesting feature of CDPD in so far as this thesis is concerned is location independence. The CDPD node is independent of service provider and location at which those services are made available. CDPD provides an end-user with a mobile node connected to other CDPD sites or the internet. CDPD implements an IPv4 application programmers interface (API); existing network programs will work unmodified over a CDPD network. This section analyzes how CDPD achieves stationary IP services despite mobile nomadic nodes, and how this possibly relates to measurement networks.
The CDPD network uses mostly standard cellular technology. A model of a CDPD network is shown in Figure 2-3.
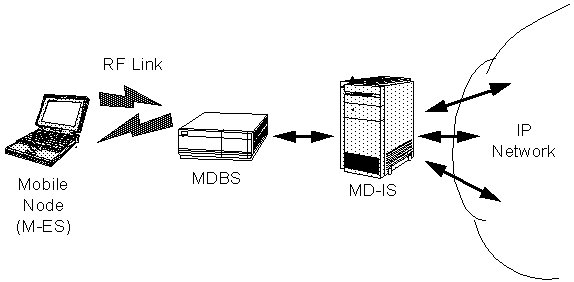
The Mobile End System (M-ES), or nomadic node, is the mobile access point to the network. The nomadic node is free to move from cell to cell (i.e.: network location) without interruption of service. The Mobile Data Base Station (MDBS) is the stationary counterpart which the nomadic node speaks to. The nomadic node will speak to different MDBS's as it moves from cell to cell. Regular cellular RF frequencies, antennae, and equipment are used for communicating between the nomadic node and the MDBS. The MDBS extracts the CDPD portion of the cellular signal and relays the data on to a central Mobile Data Intermediate System (MD-IS).
The MD-IS is the focal point of CDPD mobility management. The MD-IS is responsible for enabling the nomadic node to move around, and yet appear stationary to the rest of the network. As the nomadic node moves through the mobile environment, the MD-IS tracks it. Therefore, when packets are sent to the nomadic node, the MD-IS always knows how to reach it and knows where to forward the packet to.
The last piece of the mobile puzzle for CDPD is how to handle a hand-off when the nomadic node leaves the jurisdiction of the home MD-IS (i.e.: where the account for the nomadic entity resides). The nomadic node is always associated with its home MD-IS, regardless of where it physically resides in the cellular network. As the nomadic node moves into different MD-IS jurisdictions, the home MD-IS and local MD-IS negotiate routing information on behalf of the nomadic node. Packets sent to the nomadic node always go to the home MD-IS first. From here, they are forwarded to the current (local) MD-IS serving the nomadic node. The local MD-IS can then deliver the packets to the nomadic node.
When adding or removing nodes to a CDPD network, changes similar to regular IP are required; devices need to be assigned unique IP addresses and routing information needs to be modified (if the M-ES is a router for a subnetwork). Similarly, CDPD is on par with regular IP in its ability to handle added or removed links; routing information needs to be updated, either manually or via an automated process such as RIP.
Where CDPD really shines over IP is when a nomadic node changes physical locations. CDPD accounts for geographical mobility and "hides" it behind extra routing layers. Since packets sent to a mobile node are always sent to the home MD-IS first, the mobile node appears stationary in so far as the IP network topology is concerned. The home MD- IS tracks the current location of the nomadic node and can always forward packets to it. IP allows packets being sent from the nomadic node to the rest of the network to be routed using conventional routing techniques. Consequently, network connectivity is maintained, despite geographic and network changes, by using an extra routing layer to make the nomadic node appear stationary.
One failing of CDPD is the geography-based limitations of it; if nomadic nodes are regularly outside of the jurisdiction of their home MD-IS, there will always be extra bandwidth being consumed sending IP packets first to the home MD-IS, forwarding them to the local MD-IS, and then finally transmitting them to the nomadic node. This is a sub- optimal solution and only works well if most nodes are expected to remain within the jurisdiction of their home MD-IS.
IPv6 [26] is based largely on its predecessor, IPv4 [10]. As such, many of the issues discussed in previous sections still hold true; IPv6 is a packet-switched networking protocol with routing and network technologies. It requires special nodes to handle the tasks of configuration, maintenance, and routing. It requires a support structure of nodes and humans to maintain it. It requires protocols and programs such as RIP to use redundant links. However, IPv6 extends IP capabilities considerably over IPv4, based on the wisdom gained through the extensive implementation and use of IPv4. IPv6 is still under development; much of the standard is still in draft format. Fortunately, key components of IPv6 have become Request For Comments (RFCs), the Internet's version of a standard.
The first major change in IPv6 is the IP address format [34]. IPv6 network addresses are 128 bits long instead of 32 in IPv4. This allows the address space of IPv6 to contain address classifications as well as network location information. In combination, these allow the network address to be significantly more flexible than in IPv4.
For example, in IPv6, it is expected many network addresses will be assigned to ethernet network devices (which already have unique 48-bit MAC addresses). IPv6 allows for the lower 48 bits of the address to match the MAC address. New or mobile nodes may discover subnetwork address prefixes by listening to broadcast messaging packets [23]. This information can be combined with the ethernet MAC address to create a valid and unique network address. In this manner, a new or mobile node can generate its own valid network address without any external or manual intervention.
IPv6 includes standard protocols specifically designed to support automatic configuration of added nodes [19] [20] [54]. One such protocol, the Dynamic Host Configuration Protocol (DHCPv6) [19], provides a framework for passing configuration information to IPv6 nodes. It offers the capability of automatic allocation of reusable network addresses and additional configuration flexibility. This protocol has been specifically designed to allow a new node to be rapidly configured and provided network connectivity without human intervention. However, the configuration of the DHCP server itself must still be performed manually. So DHCP merely changes the way in which the network is configured, not the requirement for manual intervention.
IPv6 includes standard protocols designed to support nomadic nodes [15] [16] [40] [47] [49]. Each nomadic node is associated with a stationary home address. While situated away from its home, a nomadic node is also associated with a care-of address, which provides information about the nomadic node's current location. IPv6 packets addressed to a nomadic node's home address are transparently routed to its care-of address. The protocol enables IPv6 nodes to cache the binding of a nomadic node's home address with its care-of address, and to then send any packets destined for the nomadic node directly to it at this care-of address. The protocol even specifies an efficient retransmission and binding rediscovery mechanism for when the care-of address changes and cached bindings are no longer valid. In this way, not only does the nomadic node use the same network address, despite changes to its point of attachment, but traffic congestion is avoided at the home address. Furthermore, this networking scheme allows higher level connections to be maintained as the nomadic node changes its point of attachment to the network. Unfortunately, nomadic support in IPv6 requires a central authority to manage mobility for a given subnet, and requires this central authority to be housed on non-mobile nodes with static IP addresses.
Circuit switched networks mimic the original circuit-switched telephony systems used throughout the world. In their basic form, circuit switched networks allow nodes to reserve communication channels to other nodes in the network [53]. Once a reservation, or circuit, has been created, the source node may send a steady stream of data to the destination node, confident the information will arrive and in the same order it was sent, though not necessarily error-free. Once a circuit is no longer needed, it can be removed and the communication capacity is made available to other circuit creation requests.
The means by which circuits are created varies between technologies. The end result, however, is the same. Once formed, a circuit guarantees information may travel from the source to the destination at a given data rate.
A circuit may pass through many nodes between the source and destination. Each intermediary node knows exactly where to route the information it receives from the circuit. Because circuits are static once established, complex routing schemes are not required. In fact, routing for many circuit switched networks is almost trivial.
The complexity in circuit switched networks comes in the areas of path decision and circuit creation. Each technology addresses these challenges in a different way. The following sections analyze various circuit switched technologies.
The aspects of the cellular voice network relevant to this report are mainly the means by which cellular networks form and maintains circuits. Since the cellular network is not even a digital network, this section does not go very far into the details of cellular telephony.
The cellular network is a mobile voice network using both radio frequency channels and land-based lines. A circuit to a mobile node, once established, is maintained despite the mobile's movement to different "cells" or service areas. This is equivalent to nomadic nodes moving to different network addresses in IP. However, in the case of cellular, not only must network connectivity be maintained, but circuit connections must be maintained in real-time as well.
In its simplest form, cellular is merely a circuit between a mobile node and a base station. The base station is stationary and serves all of the mobile nodes within its cell. Base stations are set up so their cells overlap slightly. This allows mobile nodes to always be within range of at least one base station.
When a circuit is created to or from the mobile node, the base station allocates an RF channel for use by the circuit. The base station then transmits and receives data to and from the mobile node using this RF channel. This is fine as long as the mobile node remains within the cell (i.e.: within range of the base station). Unfortunately, mobile cellular nodes tend to travel a lot.
When a node moves away from a cell and into a new cell, a handoff occurs. The handoff consists of the old base station transferring the circuit to the new base station, thereby maintaining the circuit to the mobile node. What happens behind the scenes is the old base station merely sets up an inter-station circuit to the new base station. Thus the circuit routes through the old station, to the new station, and then to the mobile node. In this way, the mobile node leaves a circuit "trail" wherever it travels. It is assumed (and hoped) by the cellular companies that a given circuit will not persist long enough to form a very long tail.
To facilitate circuit creation to and from mobile nodes, the mobile node must always inform the closest base station of its presence. This is called "registering" with the base station. Each time the mobile node moves into a new cell, it registers with the new base station. Thereby when a call to or from the mobile node is placed, the location of the mobile node is known and the call can be routed accordingly.
Because the cellular network is designed to handle many mobile nodes moving between cells, it is extremely good at configuring new nodes and removing old nodes from its routing algorithms. The effort required to configure the network in this case is minimal. Note this is assuming the nodes being added are mobile nodes, not base stations. Base stations employ static routing methods and require substantial manual intervention to be configured.
Naturally, the cellular network is very good at handling nomadic nodes. Each node may move from cell to cell without an interruption in service (assuming the new cell has a free channel). As previously discussed, the circuit, once formed, persists and "follows" the mobile node from base station to base station.
Asynchronous Transfer Mode (ATM) [29], is a circuit switched digital networking technology. All information is transported through the network in very short packets called cells. Information flow is along paths called virtual channels or circuits set up as a series of points through the network. The packet header contains an identifier which links the packet to the correct circuit for it to take towards its destination. Packets on a particular circuit always follow the same path through the network and are delivered to the destination in the same order in which they were sent.
An ATM packet is not unlike a packet in a packet switched network; a block of user data is broken up into packets for transmission through the network. But there are significant differences between ATM and packet switched networks.
First, ATM packets are a fixed length - no more and no less. In packet switched networks the packet size has a fixed maximum but individual packet size may vary.
Secondly, ATM packets are a lot shorter. A single ATM packet does not need a complicated header. ATM packet headers only contains a pointer to a pre-configured circuit and a checksum. There is other information in the ATM packet header, such as priority bits, but is not relevant to this thesis.
Lastly, ATM packet sequence is preserved and every packet follows the exact same route through the network. Both sequence and path preservation are characteristics of circuit switched networks. This differs greatly from a packet switched network where, in some cases, every packet may take a different route to the destination, and may be duplicated (several copies of the same packet arrive), arrive out of order, or not arrive at all.
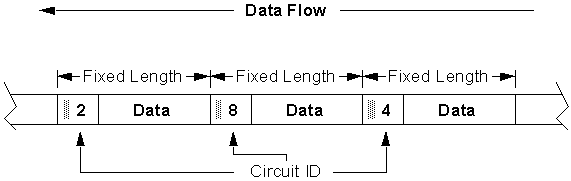
An example of a series of multiplexed ATM packets transmitted down a single physical link is shown in Figure 2-4. Note packets belonging to different logical connections, identified by the circuit ID, are transmitted one after the other on the link. The multiplexing is not fixed, however, requiring each packet to contain a circuit ID field in its header. In practice, ATM also specifies concepts for virtual paths, virtual channel links, etc. However, for this thesis, the concept of a single circuit ID identifying a route through the network is adequate.
The key concept in ATM is related to how data is routed through the network. Figure 2-5 shows an example of the circuit concept in an ATM network. At each node in the network, packets are routed based on their circuit ID. Each available circuit between two nodes has a number associated with it.
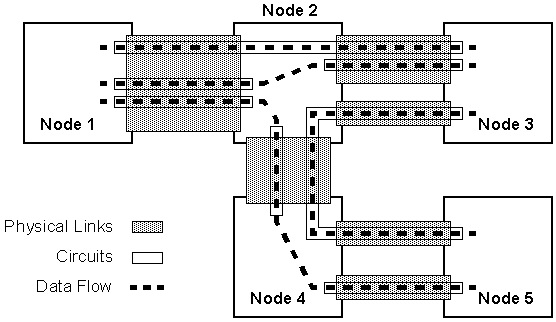
Figure 2-6 shows how a node will select the next link for a packet to be sent along. A simple lookup table of active circuits allows all of the data to be properly routed with very little delay. The circuit tables are constructed when the circuit is created.

For example, the data packet in Figure 2-6 is travelling down circuit 2. It arrives at the node illustrated from the physical link 1. The circuit table instructs the node to forward the packet to physical link 3.
The key routing algorithm in ATM is related to the method used to construct and maintain circuits. This topic is addressed in the following sections. Section 2.2.2.1 analyzes channel creation for stationary ATM networks. Section 2.2.2.2 analyzes channel maintenance in wireless and ad-hock networks.
The ATM routing mechanism is a combination of source routing and dynamic routing. Routing is only used during circuit creation; once a circuit is established, the circuit path through the network is permanent until the circuit is removed [29] [55]. To facilitate source routing, where the source node decides the path to be taken through the network, each node has to maintain a complete view of the network.
At the heart of ATM routing is the concept of a routing hierarchy. Every node in an ATM network stores a view of the entire network. An example of an ATM network can be seen in Figure 2-7. The figure shows three different views of the same network.
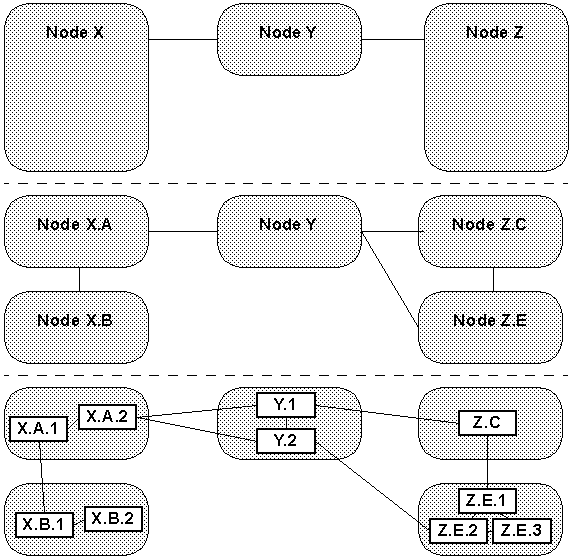
Because storing and maintaining the entire detailed network topology in every node would be difficult if not impossible, each node instead only maintains the level of network detail required to achieve its source routing. Specifically, each node only maintains knowledge of its peer nodes and the peer subnetworks above it in the network hierarchy. Figure 2-8 shows what the network of Figure 2-7 looks like to a single node (in this case, node X.B.2).
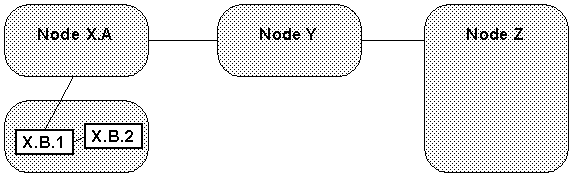
In the above network, when X.B.2 needs to route a circuit through to Z.E.1, it may route the network in the following manner: X.B.2 to X.B.1 to X.A to Y to Z. Note each time a subnetwork boundary is crossed, the next hop in the route uplinks to the next higher hierarchy layer. When the circuit is actually routed through nodes X.A, Y, and Z to the final destination, those subnetworks are responsible for finding exact routes through themselves to facilitate the circuit creation. In this way, the further a subnetwork is from a node, the less detail the node needs to know about it. This fulfills the requirements of source routing while limiting the information each node needs to store.
When a channel is routed through a subnetwork layer at which no single node can be identified (e.g.: layers X.A, Y, and Z in the above examples), a single node is designated to act on behalf of the subnetwork. This node is called the group leader. This node maintains the subnetwork's presence at the higher network layers and enables the subnetwork to appear as a single node to other subnetworks when calculating source routes. This structure is recursive and repeats itself as each higher layer is formed.
In regular ATM, adding or removing nodes must be done manually. The ATM standard provides a mechanism by which a node can discover and maintain knowledge of its neighbors and links. However, for this mechanism to operate properly, nodes must be configured with network addresses which conform to the ATM address structure.
Once all nodes have been assigned proper network addresses, the nodes will discover links and neighbors themselves. This process is recursive, just like the subnetwork addressing scheme, so that subnetworks will also discover their neighbors and links. This continues until the top-most layer is completely described to each node in the network. This eliminates the need to create and maintain complex routing tables as found in packet switched networks.
Removing a node from an ATM network is simple as long as the node is not a group leader for a subnetwork. Normally, information of the node's removal will propagate throughout the subnetwork and circuits will no longer be routed through the node. Any existing circuits to or through a node when it is removed will be lost.
Adding or removing links in an ATM network is similar in effect to adding or removing a node; information regarding the link's status will automatically propagate throughout the network. Any existing channels through a link when it becomes congested or is removed will be lost.
ATM is intolerant of nomadic nodes in a similar way to IP. A nomadic node, as it hops from subnetwork to subnetwork, changing its point of access and network address each time, will lose all existing connections (circuits) with each hop. To make matters worse, no standard ATM procedure is defined to allocate a network address to a nomadic node each time it changes its point of access. This means as the node moves from point to point, it must be manually reconfigured to use a network address suitable to its location. These restrictions render ATM inadequate to maintain connections to a nomadic node through changes in the point of access.
ATM networks may or may not contain redundant links. It is the task of the source routing algorithm to decide the path when constructing a circuit. Because of the addressing scheme employed by ATM, every node has an essentially complete picture of the network, allowing decisions between multiple paths to be made.
Wireless ATM was designed to provide ATM network connectivity to wireless mobile nodes. There are several ATM technologies which provide different aspects of automatic configuration and robustness [55]. The general scheme used for a wireless mobile ATM node is analyzed in this section.
Because changing network addresses for an ATM node would result in a loss of existing connections to the node, wireless ATM provides the ability for a single physical ATM node to keep its network address despite changes to its point of access to the network. The mechanism to accomplish this resembles a combination of CDPD with cellular hand-off operations.
Figure 2-9 illustrates a mobile ATM node as it changes its point of access to the network.

Note in the above example the Mobile ATM Switches are capable of complicated routing methods and "track" the mobile node in much the same way as the cellular network. As the node changes its access point, network connections and services are handed off to the next nearest Mobile ATM Switch.
Ultimately, the mobile ATM network may interface to a regular ATM network. This point of access to the regular ATM network remains constant and, in essence, hides the mobility aspect from the rest of the ATM network.
Wireless ATM still requires nodes to be properly identified with a valid network address before they can operate. For nodes being added to the network, this requires manual configuration. Once the network address is assigned, however, the network will automatically adjust to provide and maintain network connectivity to the node.
For nodes being removed from the network, the operation is similar as for regular ATM networks; information regarding the removal of the node propagates through the network and services to the node will be removed.
Wireless ATM responds to changes in link status similar to regular ATM. For mobile nodes changing their network point of access, link removal and creation is a regular process; the Mobile ATM Switches hand-off the connection information for the mobile node to the next nearest Mobile ATM Switch.
Wireless ATM adds the protocols and standards to ATM to facilitate rerouting when a mobile node moves. Using this method, wireless ATM maintains network connectivity for mobile nodes. However, should the Mobile ATM Switches themselves change, the effect is the same as for regular ATM networks; existing circuits are lost and the node "disappears" from its first location, and a new node "appears" in the new location.
Recently there has been a proliferation of wireless mobile computing devices. Small, often hand held, these devices demand networking on the fly to communicate with each other and the Internet. The networks formed by these devices are dynamic, always changing topology and link state as the nodes move around.
To meet the challenge of this demanding environment, a new class of routing protocols are being developed. These ad hoc routing protocols present a surprisingly close fit to the demands of measurement networks as outlined in this thesis. The following sections review the major ad hoc routing protocols. An emphasis is placed on how well the protocol meets the needs of measurement networks.
Destination-Sequenced Distance-Vector Routing (DSDV) [48] is an adaptation of conventional IP routing protocols to ad hoc networks. DSDV is based on RIP [43], used for routing in parts of the Internet. DSDV is one of the earlier ad hoc routing protocols developed.
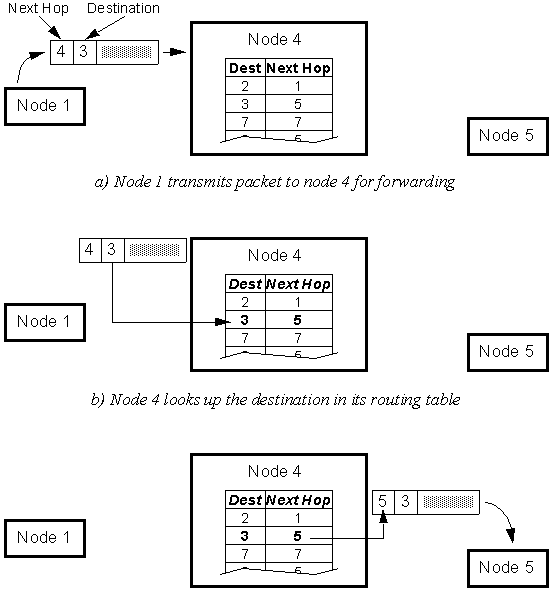
In DSDV, packets are routed between nodes of an ad hoc network using routing tables stored at each node. Each routing table contains a list of the addresses of every other node in the network. Along with each node's address, the table contains the address of the next hop for a packet to take in order to reach the node.
Figure 3-1 illustrates the routing procedure in DSDV. In this example, a packet is being sent from node 1 to node 3 (node 3 is not shown). From node 1, the next hop for the packet is node 4 (Figure 3-1 a). When node 4 receives the packet, it looks up the destination address (node 3) in its routing table (Figure 3-1 b). Node 4 then transmits the packet to the next hop as specified in the table, in this case node 5 (Figure 3-1 c). This procedure is repeated as required until the packet finally reaches its destination.
The bulk of the DSDV protocol does not involve routing at all. Rather, the crux of DSDV is the generation and maintenance of the routing tables. Every time the network topology changes, the routing table in every node needs to be updated. As one might expect, this is no trivial task. The situation is further complicated by the fact, when routing tables are out of sync (i.e. the routing protocol has not converged), routing loops may form.
To facilitate routing table generation and maintenance, several additional pieces of information are stored in the routing tables. In addition to the destination address and next hop address, routing tables maintain the route metric and the route sequence number. The route metric is an indicator of the suitability of the route: the lower the metric, the more favorable the route. The metric is often merely a count of the number of hops required to reach the destination via the route. The sequence number is used in route discovery to discern old routes from new ones. When a route is updated, the sequence number is usually incremented; if a node is exposed to two routes with equivalent source and destinations, the route with the higher sequence number is the more recently discovered route.
Periodically, or immediately when network topology changes are detected such as when a node first joins the network, each node will broadcast a routing table update packet. The update packet starts out with a metric of one. This signifies to each receiving neighbor they are one hop away from the node. The neighbors will increment this metric (in this case, to two) and then retransmit the update packet. This process repeats itself until every node in the network has received a copy of the update packet with a corresponding metric. If a node receives duplicate update packets, the node will only pay attention to the update packet with the smallest metric and ignore the rest.
To distinguish stale update packets from valid ones, each update packet is tagged by the original node with a sequence number. The sequence number is a monotonically increasing number which uniquely identifies each update packet from a given node. Consequently, if a node receives an update packet, the sequence number must be equal to or greater than the sequence number already in the routing table; otherwise the update packet is stale and ignored. If the sequence number matches the sequence number in the routing table, then the metric is compared and updated as previously discussed.
Each time an update packet is forwarded, the packet not only contains the address of the originating node, but it also contains the address of the transmitting node. The address of the transmitting node is entered into the routing table as the next hop (unless the packet is ignored, of course). Figure 3-2 illustrates how a node processes an update packet under varying conditions. Note update packets with higher sequence numbers are always entered into the routing table, regardless of whether they have a higher metric or not.

Mobile nodes cause broken links as they move from place to place. The broken link may be detected by the communication hardware, or it may be inferred if no broadcasts have been received for a while from a former neighbor. A broken link is described as having a metric of infinity. Since this qualifies as a substantial route change, the detecting node will broadcast an update packet on behalf of the lost destination. This update packet will have a new sequence number and a metric of infinity. This will essentially cause the routing table entries for the lost node to be flushed from the network. Routes to the lost node will be established again when the lost node sends out its next broadcast update packet.
When a mobile node moves in the network, the possibility exists for the mobile node and its previous neighbors to both simultaneously send update packets to advertise the topology change. The mobile node sends update packets as part of its normal operation. The previous neighbors send update packets to advertise the loss of the network link to the mobile node. If both the mobile node and the previous neighbors use the same sequence number in their update packets, the update packets will conflict with each other. To avoid this situation, regular update packets only contain even sequence numbers, and update packets sent by previous neighbors to advertise lost links only contain odd sequence numbers.
DSDV contains substantially more procedures for handling higher layer addresses, dealing with non-mobile base stations, and damping fluctuations caused by topology changes. However, details describing these procedures are deemed beyond the scope of this thesis. For more information, refer to [48].
DSDV is based on a conventional routing protocol, RIP, adapted for use in ad hoc networks. Routing is achieved by using routing tables maintained by each node. The bulk of the complexity in DSDV is in generating and maintaining these routing tables.
DSDV requires nodes to periodically transmit routing table update packets, regardless of network traffic. These update packets are broadcast throughout the network so every node in the network knows how to reach every other node. As the number of nodes in the network grows, the size of the routing tables and the bandwidth required to update them also grows. This overhead is DSDV's main weakness, as Broch et al. [21] found in their simulations of 50-node networks. Furthermore, whenever the topology changes, DSDV becomes unstable until update packets propagate throughout the network. Broch found DSDV to have the most trouble (of four protocols analyzed) in dealing with high rates of node mobility.
Temporally-Ordered Routing Algorithm (TORA) [46] is a distributed routing protocol based on a "link reversal" algorithm. It is designed to discover routes on demand, provide multiple routes to a destination, establish routes quickly, and minimize communication overhead by localizing the reaction to topological changes when possible. Route optimality (shortest-path routing) is considered of secondary importance, and longer routes are often used to avoid the overhead of discovering newer routes. It is also not necessary (nor desirable) to maintain routes between every source/destination pair at all times.
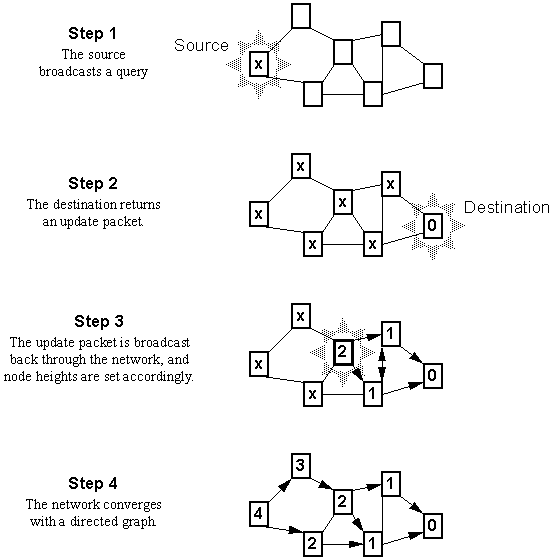
The actions taken by TORA can be described in terms of water flowing downhill from the source node towards the destination node through a network of tubes that model the routing state of the network. The tubes represent links between nodes in the network, the junctions of the tubes represent the nodes, and the water in the tubes represents the packets flowing towards the destination. Each node has a height which is computed by the routing protocol. If a tube between two nodes becomes blocked such that water can no longer flow through it, the height of the nodes are set to a height greater than that of any neighboring nodes, such that water will now flow back out of the blocked tube and find an alternate path to the destination.
At each node in the network, a logically separate instance of TORA is run for each destination. When a node needs a route to a particular destination, it broadcasts a route query packet containing the address of the destination. This packet propagates through the network until it reaches either the destination or an intermediate node which already has a route to the destination. The recipient of the query packet then broadcasts an update packet listing its height with respect to the destination (if the recipient is the destination, this height is 0). As this packet propagates back through the network, each node that receives the update sets its height to a value greater than the height of the neighbor from which the update was received. This has the effect of creating a series of directed links from the original sender of the query to the node that initially generated the update. An example of this process is illustrated in Figure 3-3.
When a node discovers a route to a destination is no longer valid, it adjusts its height so that it is a local maximum with respect to its neighbors and transmits an update packet. This process is illustrated in Figure 3-4.
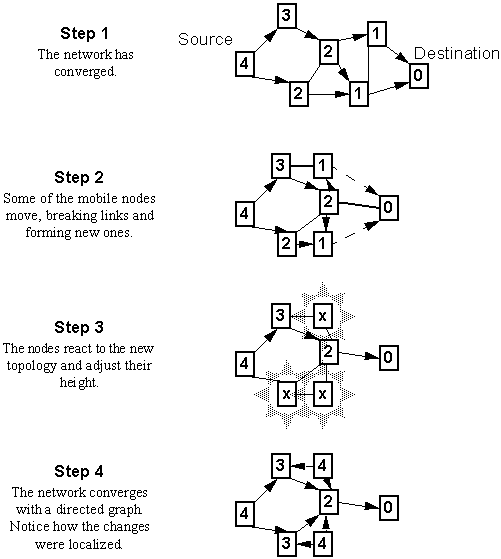
When a node detects a network partition, where a part of the network is physically separated from the destination, the node generates a clear packet that resets routing state and removes invalid routes from the network.
TORA sits as a routing layer above another, network level protocol called the Internet MANET Encapsulation Protocol (IMEP) [25]. IMEP is designed to support the operation of many routing algorithms, network control protocols or other upper layer protocols intended for use in mobile ad hoc networks. The protocol incorporates mechanisms for supporting link status and neighbor connectivity sensing, control packet aggregation and encapsulation, one-hop neighbor broadcast reliability, multipoint relaying, network-layer address resolution, and provides hooks for interrouter authentication procedures.
TORA is one of the largest and most complicated protocols presented in this thesis. In terms of memory requirements, each node must maintain a structure describing the node's height as well as the status of all connected links per connection supported by the network [46]. In terms of CPU and bandwidth requirements, each node must be in constant coordination with neighboring nodes in order to detect and respond to topology changes. As was found with DSDV, routing loops can occur while the network is reacting to a change in topology [21] [46].
TORA is designed to carry IP traffic over wireless links in an ad hoc network. Based on simulation results [21] [45], it is best suited to large, densely packed arrays of nodes with very low node mobility (although Broch [21] calls into question the validity of Park and Corson's simulations in [45] supporting this claim). Of the two papers reporting simulation results, only the one by Broch et al. [21] actually simulates node mobility. Broch found TORA to be encumbered by its layering on top of IMEP, and found IMEP caused considerable congestion when TORA was trying to converge in response to node mobility. This resulted in TORA requiring between one to two orders of magnitude more routing overhead than other ad hoc routing protocols investigated by Broch in [21].
Dynamic Source Routing (DSR) [39] [38] is designed to allow nodes to dynamically discover routes across multiple network hops to any destination in the ad hoc network. When using source routing, each packet to be routed carries in its header the complete, ordered list of nodes through which the packet must pass. A key advantage of source routing is intermediate hops do not need to maintain routing information in order to route the packets they receive; the packets themselves already contain all necessary routing information. An example of a packet moving through an ad hoc network with source routing is illustrated in Figure 3-5.
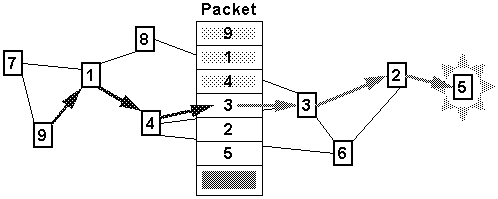
Unlike every other protocol presented in this thesis, DSR does not require the periodic transmission of router advertisements or link status packets, reducing the overhead of DSR. In addition, DSR has been designed to compute correct routes in the presence of unidirectional links.
Source routing is a routing technique in which the sender of a packet determines the complete sequence of nodes through which to forward the packet. The sender explicitly lists this path in the packet's header, identifying each "hop" by the address of the next node to which to transmit the packet on its way to the destination host.
DSR is broken down into three functional components: routing, route discovery and route maintenance. Routing has already been described above and is relatively trivial. Route discovery is the mechanism by which a node wishing to send a packet to a destination obtains a path to the destination. Route maintenance is the mechanism by which a node detects a break in its source route and obtains a corrected route.
To perform route discovery, the source node broadcasts a route request packet with a source route listing only itself. Each node that hears the route request adds its own address to the source route in the packet and forwards the packet to its neighbours. The route request packet propagates hop-by-hop outward from the source node until either the destination node is found or until another node is found which can supply a route to the target.
Nodes forward route requests if they are not the destination node and they are not already listed as a hop in the route. In addition, each node maintains a cache of recently received route requests and does not propagate any copies of a route request packet after the first.
All source routes learned by a node are kept (memory permitting) in a route cache. This cache is used to further reduce the cost of route discovery. A node may learn of routes from virtually any packet the node forwards or overhears. When a node wishes to send a packet, it performs route discovery only if no suitable source route is found in its cache.
Further, when a node receives a route request for which it has a route in its cache, it does not propagate the route request, but instead returns a route reply to the source node. The route reply contains the full concatenation of the route from the source, and the cached route leading to the destination.
Conventional routing protocols integrate route discovery with route maintenance by continuously sending periodic routing updates. If the status of a link or node changes, the periodic updates will eventually propagate the change to all other nodes, presumably resulting in the computation of new routes. However, using dynamic route discovery in DSR, there are no periodic messages of any kind from any of the nodes. Instead, while a route is in use, the route maintenance procedure monitors the operation of the route and informs the sender of any routing errors.
If a node along the path of a packet detects an error, the node returns a route error packet to the sender. The route error packet contains the address of the hosts at both ends of the link in error. When a route error packet is received or overheard, the hop in error is removed from any route caches and all routes which contain this hop must be truncated at that point.
There are many methods of returning a route error packet to the sender. The easiest of these, which is only applicable in networks which use bidirectional links exclusively, is to simply reverse the route contained in the packet from the original host. If unidirectional links are used in the network, the DSR protocol presents several alternative methods of returning route error packets to the sender.
Route maintenance can also be performed using end-to-end acknowledgments rather than the hop-by-hop acknowledgments described above. As long as some route exists by which the two end hosts can communicate, route maintenance is possible. In this case, existing transport or application level acknowledgments, or explicitly requested network level acknowledgments, may be used to indicate the status of the route.
Two sources of bandwidth overhead in DSR are route discovery and route maintenance. These occur when new routes need to be discovered or when the network topology changes [39] [37]. However, this overhead can be reduced by employing intelligent caching techniques in each node, at the expense of memory and CPU resources. The remaining source of bandwidth overhead is the required source route header included in every packet. This overhead cannot be reduced by techniques outlined in the DSR literature.
DSR simulation results have been reported in numerous papers, [38], [21], and [37] to name a few. In [21], Broch et al. found DSR to perform the best of four protocols simulated in their scenarios. Unfortunately, Broch only simulated networks of 50 nodes; as node count increases, the detrimental effects of route discovery and maintenance can be expected to grow.
The virtual subnet protocol (VS) [51] [52] partitions a large body of nodes into smaller groups called subnets. It applies a hierarchical addressing schemes to these subnets. A novel routing scheme is then employed to enable broadcasting within subnets and limited broadcasting between subnets. The virtual subnet addressing scheme is somewhat reminiscent of that used in ATM [29].
In this method, network nodes are assigned addresses depending on their current physical connectivity. Assume the network is segmented into physical subnets, each containing mobile nodes (the distinction between physical and virtual subnets will be clarified shortly; for the moment assume that physical subnets cover a local area). Each node in the network is assigned a unique address constructed of two parts: one part is a subnet address allocated to the entire subnet (subnet_id), and the other part is an address which is unique within the node's subnet (node_id). In this thesis, this address is written as subnet_id.node_id (e.g.: 12.2, 5.3).
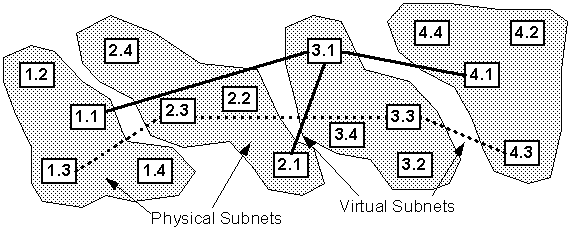
Each node in this topology is affiliated with nodes whose address differs only in one digit; that is, node x1.x0 is affiliated with nodes x1.x0/ and x1/.x0 Thus, every node is affiliated with every node within its subnet, as well as one node in every other subnet. These cross- linked affiliations are the building blocks of the ad hoc network. Figure 3-6 illustrates a network arranged in this fashion.
Each node in the network is affiliated with a physical subnet (the local nodes all sharing the same subnet_id) and a virtual subnet (the remote nodes all sharing the same node_id). Nodes which are members of a physical subnet (subnet_id) are within close proximity in a local geographic area. Nodes which are members of a virtual subnet (node_id) form a regional network (i.e., beyond a local area).
A node becomes a member of a physical subnet by acquiring the first available address (with the lowest node_id) in that subnet. Once a node becomes affiliated with a specific physical subnet, it automatically becomes a member of a virtual subnet defined by the node_id in its address. As long as a node remains within "hearing" distance of its subnet neighbors, it will keep its current physical subnet affiliation and its address.
When a node moves to a new location where it cannot establish a connection with its previous physical subnet's members, it will drop its previous address and join a new physical subnet.
In the simple case where the destination node is within two hops of the source node, packets traverse one network address digit at a time in fixed order. For example, when the source node address is 12.15 and the destination node address is 9.17, the packet would follow the route: 12.15 to 12.17 to 9.17. In this case, routing requires at most two hops.
In general, the network will be arranged such that more than two hops are necessary from source to destination. In this case the routing is performed in two phases. In the first phase, routing is performed only in the physical subnet. Packets are routed to the node belonging to the same virtual subnet as the destination. Using the same example as above, phase one consists of routing packets from 12.15 to 12.17.
In phase two, packets are routed between virtual subnets. The papers describing virtual subnets by Sharony [51] [52] become especially sketchy at this stage of the protocol. The papers call for adjustments of transmission frequencies, transmission power, and/or directional antennae to facilitate logical network connections. It must be assumed all nodes are capable of reaching neighboring physical subnets when required to do so. However, the papers still do not describe how subnets become aware of, and plot routes through, neighboring subnets.
The VS protocol, as currently specified, can best be described as a method to optimize throughput when multiple frequencies and/or spatial reuse is possible, on the condition nodes are close together relative to their transmitter range. Virtual subnets have been analyzed using queueing theory, but no actual simulations or implementations have been studied. Furthermore, there are apparent holes in the proposed routing mechanism regarding forwarding of packets between subnets.
It should also be noted VS may require a change in network address in response to a topology change. Consequently, any existing network connections to the affected nodes will be lost. This is akin to similar problems in IP networks.
Various routing protocols exist other than those presented in previous sections. For the most part, these routing protocols offer improvements to the protocols already discussed. This sections highlights the improvements or novel applications these protocols offer without repeating concepts presented in previous sections.
Ad Hoc On-Demand Distance Vector (AODV) [50] routing is essentially a combination of both DSR (Section 3.3) and DSDV (Section 3.1). It borrows the basic on-demand mechanism of route discovery and route maintenance from DSR, plus the use of hop-by- hop routing, sequence numbers, and periodic update packets from DSDV.
The main benefit of AODV over DSR is the source route does not need to be included with each packet. This results in a reduction of routing protocol overhead. Unfortunately, AODV requires periodic updates which, based on simulations by Broch [21], consume more bandwidth than is saved from not including route information in the headers.
The signal stability based adaptive routing protocol (SSA) [28] is a variant of AODV (Section 3.5.1) to take advantage of information available at the link level. Both the signal quality of links and link congestion are taken into consideration when finding routes. It is assumed, by selecting links with strong signals, links will change state less frequently and the number of route discovery operations will be reduced. Link signal strength is measured when the nodes transmit periodic hello packets.
One important difference of SSA from AODV or DSR is that paths with strong signal links are favored over optimal paths. While this may increase the hop count of routes, it is hoped discovered routes will survive longer.
The cluster based routing protocol (CBRP) [36] is a variation of the DSR protocol (Section 3.3). CBRP groups nodes located physically close together into clusters. Each cluster elects a cluster head. The cluster head maintains complete knowledge of cluster membership and inter-cluster members (called gateways) which have access to neighboring clusters.
The main difference between DSR and CBRP is during the route discovery operation. DSR floods route query packets throughout the entire network. CBRP takes advantage of its cluster structure to limit the scope of route query flooding. In CBRP, only the cluster heads (and corresponding gateways) are flooded with query packets, reducing the bandwidth required by the route discovery mechanism.
Unfortunately, CBRP depends on nodes transmitting periodic hello packets; a large part of the gains made by DSR are because DSR does not require periodic packets of any kind.
Optimized Link State Routing (OLSR) [35] is a link state routing protocol. OLSR is an adaptation of conventional routing protocols to work in an ad hoc network on top of IMEP [25].
The novel attribute of OLSR is its ability to track and use multi-point relays. The idea of multi-point relays is to minimize the flooding of broadcast messages in the network by reducing/optimizing duplicate re-transmissions in the same region. Each node in the network selects a set of nodes in its neighborhood who will re-transmit its broadcast packets. This set of selected neighbor nodes is called the multi-point relays of that node. Each node selects its multi-point relay set in a manner to cover all the nodes that are two hops away from it. The neighbors which are not in the multi-point relay set still receive and process broadcast packets but do not re-transmit them. Figure 3-7 illustrates an example of multi-point relay versus regular flood broadcasting in a network of 10 nodes.

The Zone Routing Protocol (ZRP) [33] is a hybrid of DSR (Section 3.3), DSDV (Section 3.1), and OLSR (Section 3.5.4). In ZRP, each node pro-actively maintains a zone around itself using a protocol such as DSDV. The zone consists of all nodes within a certain number of hops, called the zone radius, away from the node. Each node knows the best path to each other node within its zone. The nodes which are on the edges of the zone (i.e.: are exactly zone_radius hops from the node) are called border nodes, and are employed in a similar fashion to multi-point relays in OLSR.
When a node needs to route a packet, it first checks to see if the destination node is within its zone. If it is, the node knows exactly how to route to the destination. Otherwise, a route search similar to DSR is employed. However, to reduce redundant route search broadcasts, nodes only transmit route query packets to the border nodes (called bordercasting). When the border nodes receive the search query packet, they repeat the process for their own zones.
Because ZRP only employs pro-active network management in a local zone, overhead is reduced over protocols like DSDV. When route discovery procedures are employed as in DSR, overhead is reduced by limiting the query packet broadcasts to border nodes.
Fisheye State Routing (FSR) [31] is a combination of DSDV (Section 3.1) and TORA (Section 3.2). Each node maintains a routing table of how to reach every other node in the network, similar to DSDV except full topology information is maintained at each node. Each node uses this information to route packets through the network. FSR maintains the routing table with periodic link state (hello) packets which propagate a set distance through the network as defined by the scope. Hello packets with a larger scope (and which propagate further) are transmitted less frequently. Thus the further away a destination node is, the less reliable the routing information. However, a packet in transit to a distant node will be routed with more accurate information as it approaches the destination.
There seem to be an ever-increasing flow of proposed ad hoc routing protocols since 1999. Unfortunately, most seem to provide little additional performance or insight over the protocols already developed. Some protocols, such as the Relative Distance Micro- discovery Ad Hoc Routing protocol [14] and the Source Tree Adaptive Routing Protocol [30] make sudden appearances and equally sudden disappearances in the Mobile Ad-hoc Networks working group of the IETF. Others merely re-hash existing ideas under new names. For example, the Landmark Routing Protocol [32] is almost identical in concept and operation to CBRP (Section 3.5.3) except for the capability to use alternate routing protocols within local clusters (and changing the name of the "cluster head" to "landmark"). There are advances being made in some areas, such as by the INSIGNIA protocol [17] [41] which deals with quality of service issues, but such issues are beyond the scope of this thesis. To maintain focus and brevity, this thesis does not explore further into these ad hoc routing protocols which provide marginal relevance to the discussion herein.
It is interesting within the context of this thesis to investigate the impact an ad hoc routing protocol may have on a measurement network. In particular, it is useful to discuss implications which may not be inherently obvious without further analysis.
Section 4.1 discusses the impact of multiple interfaces on node construction and resource requirements. Section 4.2 investigates the role of redundancy in measurement networks and discusses the primary benefits and potential pitfalls of redundancy. Section 4.3 introduces the implications of multiple hops on queueing and buffers as compared to single hop networks. Section 4.4 briefly introduces the impact of multiple hops on packet latency. Finally, Section 4.5 provides a summary of the conclusions of this chapter.
In typical measurement networks, nodes have only a single interface connecting them to the single wired communications medium. Should the communication medium employ wireless technologies, a single network interface may effectively operate as though it is multiple interfaces. This thesis, however, focuses on wired communication mediums where this does not typically occur.
In order to implement multiple links as suggested in this thesis, nodes must have two or more interfaces so a single node can be simultaneously connected to several subnetworks and act as a bridge between these subnetworks.
Multiple interfaces likely requires increased complexity and chip count when designing and building the node. Considering a single interface may represent a significant portion of the cost in building the node, both in money and in printed circuit board real estate, adding multiple interfaces to a node may prove expensive.
The CPUs used in measurement networks, as discussed in Section 1.3.1, generally have limited processing capabilities. The increased workload from servicing multiple interfaces, handling other node's traffic, and implementing a routing protocol may require increased memory and CPU resources.
In dealing with network cables, typically the most costly and error prone component is the connector to the node. In systems which require weatherproofing or environmental sealing, the difficulty of getting the cable through a protective case can also be significant. With multiple interfaces, these problems are aggravated.
Redundancy in networks, as in most systems, seems intuitively better for robustness and fault tolerance. Implementing ad hoc routing in measurement networks enables measurement networks to benefit from redundant links. It is useful, therefore, to quantify some of the benefits gained from, and limitations of redundancy.
Section 4.2.1 introduces the elementary statistics of redundancy in networks. Section 4.2.2 describes how probability distributions were discretely manipulated for this thesis. Sections 4.2.3 through 4.2.5 further analyze specific effects of redundancy. Finally, Section 4.2.6 discusses the importance and impact of failure modes on failure probability distributions.
Figure 4-1 shows a network composed of two nodes connected by the single link A. For this example, PFail_A represents the probability of failure for link A. That is, network traffic is successfully carried across link A with a probability of (1-PFail_A), neglecting any losses due to packet corruption, partial packets, and so forth.

In this simplified example it is easy to see, at any point in time, the probability of network traffic being successfully transmitted from one node to the other is equal to (1-PFail_A). Should link A fail, network traffic cannot be transmitted between the nodes, and the network has become partitioned. Thus we may say the network becomes partitioned with a probability of Ppartitioned=PFail_A.
Figure 4-2 shows a network composed of the same two nodes, except now there are two links able to carry network traffic between them.
As an example, let us assume node 1 and node 2 are aware of and capable of using both link A and link B. Furthermore, let us assume the probability of link A and link B failure is represented by PFail_A and PFail_B respectively. Finally, let us assume PFail_A and PFail_B are independent.
In this example, The four possible network states are: A and B are both working, A alone is working, B alone is working, neither A nor B is working. The network will become partitioned if link A and link B both fail. Consequently, the addition of a redundant link to the network has changed Pparitioned to a new value Pparitioned= (PFail_A intersection PFail_B). This is beneficial as it is expected (PFail_A intersection PFail_B)<PFail_A.
The analysis so far is useful for understanding the impact of redundancy at its simplest level. However, the above analysis assumes link failures are periodic and will be removed with equal probability of their occurring. In a measurement network, these assumptions are not necessarily valid; once a link fails, it will most likely remain so until physically repaired.
The question then becomes how does redundancy impact the failure probability density function (PDF). Put another way, how does link redundancy impact (and hopefully prevent) network partitioning over the lifetime of the network.
Let's start again with a simple example network composed of two nodes.

In Figure 4-3, link A has a failure PDF of DFail_A. In this example, DFail_A is assumed to have a shape similar to a bell curve without any failures before time t=0 (a network cannot fail before it exists). The graph for DFail_A depicts arbitrary time units along the X axis. The total area under the graph of DFail_A equals 1. That is:
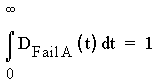
|
(4-1) |
This tells us at t = o all links have failed. Because DFail_A is a probability distribution, given two times ta and tb, the probability of failure of link A, PFail_A, is given by the formula:
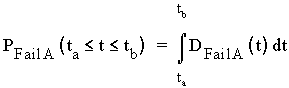
|
(4-2) |
Because the area under the graph must always equal 1, the vertical axis' scale is relative. Furthermore, this thesis is interested in general trends, not absolute values for any particular experiment or network configuration. Therefore the vertical axes are generally left unnumbered. The vertical axes are always linear unless explicitly labeled otherwise.
In Figure 4-3, the PDF depicting network partitioning Dpartitioned matches DFail_A (Dpartitioned = DFail_A); should link A fail, the network becomes partitioned. We are interested to see what affect, if any, a second link introduced between node 1 and node 2 will have on Dpartitioned. This scenario is illustrated in Figure 4-4. In this example, it is assumed DFail_A = DFail_B. In Figure 4-4, Dpartitioned for the two-link case is shaded in grey; Dpartitioned for the one-link case from Figure 4-3 is indicated by a broken line and is included for comparison purposes.
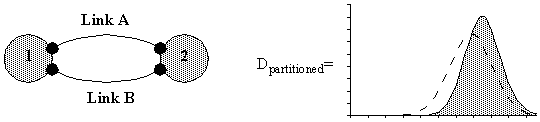
The derivation of Dpartitioned for the two link scenario involves discretely calculating Dpartitioned using a computer algorithm and is described in Section 4.2.2.
There are three primary effects of redundancy relevant to this investigation. First and most evident is a shifting of the failure PDF to the right (greater in time). The distribution also becomes more concentrated, a fact that can be seen by the rise in the relative height of the distribution peak in Figure 4-4. The second effect is a significant decrease in the number of failures during the early stages of the lifetime of the network. This effect is not overtly obvious in Figure 4-4 and is better shown with a logarithmic Y-axis. The final effect is the ability to detect the majority of early failures and yet avoid network partitioning. These benefits will be discussed in more detail in sections 4.2.3 through 4.2.5.
There are two ways in which PDFs may be combined. The traditional method involves approximating the distributions with formulae and manipulating the formulae algebraically. The alternative is to approximate the distributions with a series of discrete values and combine them graphically using a computer. The second method was employed for this thesis because it requires less mathematical expertise and allows for manipulation of arbitrary probability distributions. This method is very similar to fault trees and event trees [44] used to calculate probabilities for extremely complex systems such as the chance of a meltdown in a nuclear reactors. This method is also similar to tree diagrams as described in [27].
In the following discussions, graphs and formats are borrowed from probability and statistics. The horizontal axis of distribution curves is always in arbitrary units of time. The area under distribution curves always equals 1.0 and represents the complete sample set or set of possible events. The vertical axis is relative and is only relevant to the corresponding graph.
The first step of combining PDFs discretely involves approximating the PDF with a finite set of discrete values. Each value represents an equally spaced probability. Put another way, the distribution is sampled or digitized. Figure 4-5 shows a PDF which has been sampled into three discrete values.
Calculations involving the combination of two failure distributions can be done graphically. An example of the process follows.
In Figure 4-6, two nodes are connected by two links. The links A and B have failure PDFs DFail_A and DFail_B equivalent to Dfailure as shown in Figure 4-5.
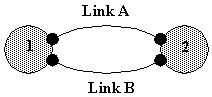
In this example, it is assumed node 1 and node 2 are aware of and capable of using both link A and link B. It is also assumed the failure modes of links A and B are independent; the failure of one link in no way affects the failure of the other link. In this example the network will become partitioned only if both links A and B fail.
For each discrete time value in DFail_A and DFail_B a graph is drawn representing the probability of each possible network state. Because each discrete value of the PDF represent a probability of failure for a given time range, the discrete PDF values can be combined as simple probabilities.
This is illustrated in Figure 4-7 where a square represents all possible states, a lightly shaded region represents a failure of one link, and a dark region represents a failure of both links. In Figure 4-7 a, there are four distinct networks states: both link A and B are operational (P=0.5625), link A alone has failed (P=0.1875), link B alone has failed (P=0.1875), and both links A and B have failed (P=0.0625). Notice the sum of the previous four values equals 1, representing the total sample set and also the total area within the box. Furthermore, the failure of link A and link B are independent.
At this point, only one case results in network partitioning: Link A and Link B both fail. The probability of this occurring at t=1 (Figure 4-7 a) is P=0.0625. Thus our value for Dpartitioned for t=1 is 0.0625. This value is entered into the graph of Dpartitioned at the right hand side of Figure 4-7 (a).
The complete derivation of Dpartitioned involves calculating the probability of failure in this manner one discrete time value at a time as shown in Figure 4-7. When all discrete values of Dpartitioned are calculated, the correctness of the calculation may be checked by ensuring the area under the graph for Dpartitioned still equals 1.0.
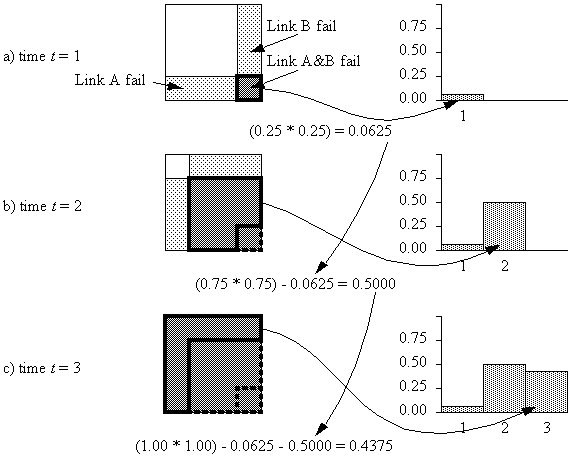
To perform more complicated calculations with n nodes connected by m links, a computer algorithm is employed. In this algorithm, each discrete time interval is analyzed using a binary tree. The binary tree has a layer of branches for each network link. At the leaves of the tree, every possible network state is represented. Each network state is then evaluated to determine if the state results in network partitioning; if it does, the probability of the state occurring is calculated similar to the example in Figure 4-7. The probabilities for the states resulting in partitioning are summed together to derive Dpartitioned for that discrete time value. The calculation for Dpartitioned at t=2 for a three-node three-link network is illustrated in Figure 4-8.
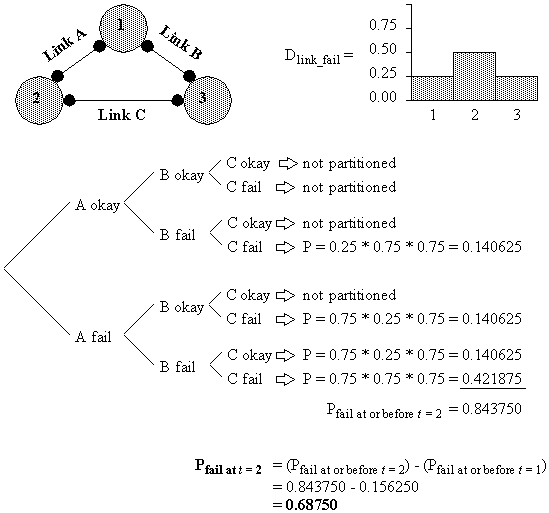
Although the above examples use uniform PDFs and independent failure modes, it is relatively easy to integrate into the calculation links with different failure PDFs and any range of failure modes from fully dependent to fully independent. Unfortunately, for large networks with many nodes and links, this method becomes difficult to manage; the binary tree grows exponentially with each additional link.
As can be seen in Figure 4-4, the most obvious effect of redundancy is to concentrate the failure distribution and shift it to the right. This phenomenon tends to occur when the primary failure modes are independent. This occurs because link failures which would cause network partitioning in a non-redundant network must await further link failures in a redundant network before causing network partitioning. This dependency of failures tends to procrastinate network partitioning. Failure modes are discussed in more detail in Section 4.2.6.
To illustrate this phenomenon, Figure 4-9 contains examples of arbitrary link failure PDFs and the resulting network partitioning PDF when a single redundant link is added to a four-node network. All graphs in Figure 4-9 are made to the same scale. The single-link failure PDF is shown in the first column. In the last column, the non-redundant partitioning PDF is shown by a broken line for comparison.
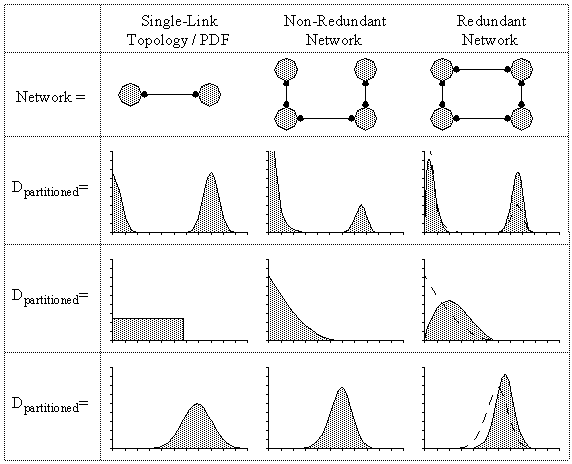
One may wonder why, in Figure 4-9, the three-link network failure PDF (middle column) appear much worse than the first column. The answer is simple. In the first column, the graph shows the chance one link out of one will fail. The middle column shows the chance one link out of three will fail (a single link failure will partition the network). Essentially, there are three times the chances for failure. Based on this observation, it would seem adding a fourth link is a bad idea, and indeed in some respects it is; adding a fourth link offers four times the chances for a single link failure. However, because the fourth link introduces redundancy, Dpartitioned does not reflect the chance of 1 of 4 links failing; a single link failing does not partition the network! In the four-link case, Dpartitioned reflects the chance of 2 of 4 links failing because 2 links must fail in order for the network to become partitioned. Thus Dpartitioned improves visibly by the addition of a redundant fourth link.
The discussion so far may be interpreted to imply redundancy alone can extend a network's expected lifetime. Although a shifting of failures further into the future is present to a degree, this shift is not necessarily significant in comparison to a system's total lifetime. Each link in a network has its own failure PDF and, after a point, each link will likely fail; redundancy cannot change this fact.
This is illustrated in Figure 4-10; Dpartitioned for a two-node network was calculated with one, five, 10, and 20 links. As can be seen, the impact additional links have on Dpartitioned decreases as the number of redundant links grow. It should be noted in Figure 4-10 the origin does not necessarily correspond to t=0. Consequently, while redundancy can be used to shift Dpartitioned favorably into the future, the significance of the shift is relative and may be very small.
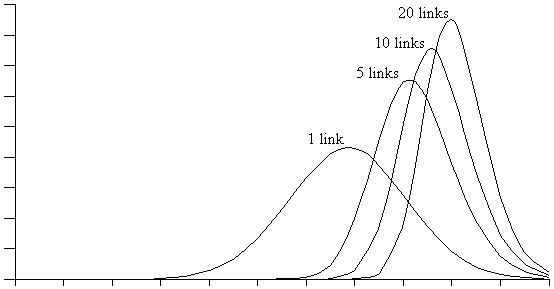
Arguably the most significant benefit redundancy provides occurs in the early stages of a system's lifetime. For distributions where relatively few failures occur during the initial portions of the PDF, redundancy significantly reduces the number of failures in the early portions of the network's lifetime. This is because the redundancy in the network tends to procrastinate network partitioning. Figure 4-11 illustrates this effect; the four-node networks from Figure 4-9 were used with a bell-like Dlink_failure. Plots for the three and four link case are plotted on the same graph showing Dpartitioned (a) and log(Dpartitioned) (b).
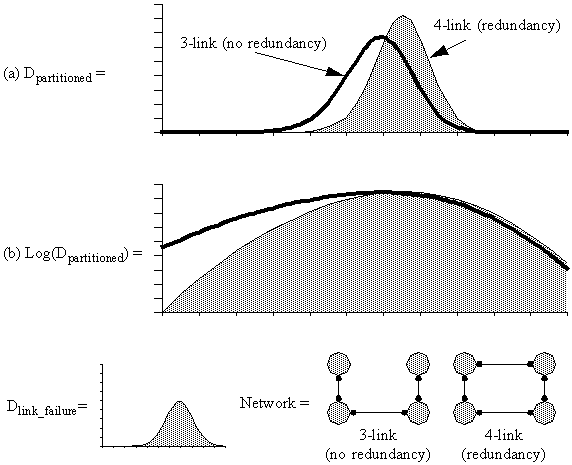
Notice in Figure 4-11 (b) the discrepancy between the three and four link case. The four link case has a single redundant link. This redundancy has significantly reduced the number of failures during the first part of the graph. Remember Figure 4-11(b) is logarithmic; the difference between the plots in Figure 4-11(b) may represent several orders of magnitude (depending on the shape of Dlink_failure).
At this point, one might question the value of this phenomenon; is this decrease in early stage failures worth it? There is always a point after which the bulk of the network components will soon fail. At this point, the entire network will probably have to be replaced. Redundancy cannot change this. What Figure 4-11 shows is redundancy can be used to reduce the number of network failures before system-wide replacement of components is necessary. And as Figure 4-11(b) shows, the number of reduced failures may be significant.
Unfortunately, this benefit of redundancy is only present when Dlink_failure has relatively few failures in the early portion of the PDF such as bell-like distributions. When distributions are more evenly distributed, this effect is less evident. More specifically, this phenomenon is not significant where there are a large number of failures in the early part of the distribution. For example, Dpartitioned and log(Dpartitioned) were again plotted as in Figure 4-11, except Dlink_failure was assumed to have two humps. This is illustrated in Figure 4-12.
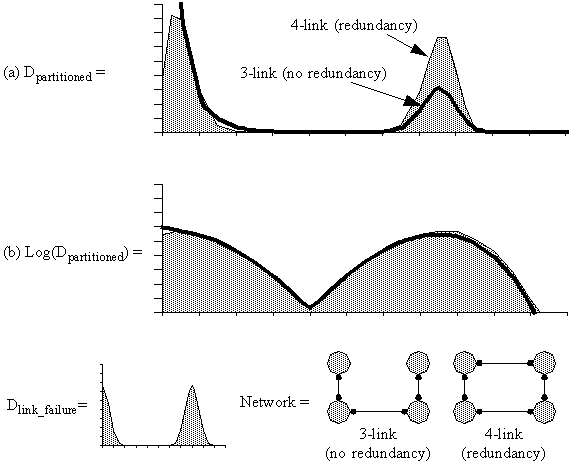
As can be seen in Figure 4-12, for some distributions the reduction of failures in the early stages of the network's lifetime can be small. The critical element here is a good understanding of Dlink_failure. This allows the network designer to calculate the impact redundancy will have on the network. Without a good knowledge of Dlink_failure, the effects of redundancy are uncertain.
When redundancy is introduced into a network by the addition of links, the chance at least one link will fail increases; there are more links, therefore there are more chances for link failure. However, the redundancy in the network generally reduces the chance network partitioning will occur. If we look at the distributions for these two cases, we get an interesting picture. Figure 4-13 illustrates the PDF curves for Done_or_more_link_failure and Dtwo_or_more_link_failures = Dpartitioned for a four-node, four-link network with redundancy (the network and link failure PDF are shown at the bottom of Figure 4-13).
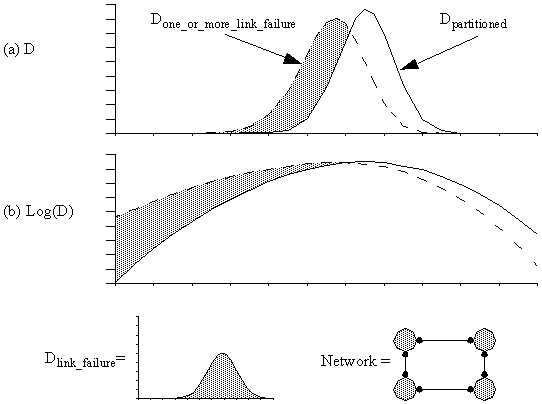
The exciting characteristic of this situation is all the failures between the two curves are non-critical failures (the shaded area in Figure 4-13). That is, these are failures involving at least one link, but they will not cause network partitioning. If the nodes support even a primitive link status capability, these failures will be detectable and reportable over the network. As Figure 4-13 shows, redundancy enables a large number of early link failures to be detected and reported while maintaining network integrity.
The consequences of this in terms of network maintenance may be significant. Maintenance alarms can be signaled without critically impacting the functionality of the network. If situations demand it, the network may be serviceable while in-service; this would result in a network extremely resistant to network partitioning and highly maintainable. Detailed investigations into redundancy and maintenance issues are beyond the scope of this thesis and are left as a topic for future study.
The limitations of non-critical failures are essentially the same as for early stage effects; the degree to which redundancy will help hinges on the link failure PDF curve. If the curve has significant failures in the early stages of the network's lifetime, redundancy effects will be present but reduced. If early link failures are relatively rare, benefits may be significant.
A failure mode is the cause or reason for failure. Different failure modes may affect different parts of a network and may cause different results. It is important to have an understanding of the failure modes for an application because some failure modes negate redundancy effects. In extreme cases, redundancy can even be detrimental and increase the probability of failure.
This is best illustrated using an example. A mechanic at a garage has two sensor nodes connected by a network. One node is inside the garage and one is outside. The mechanic has laid network cable between them through the garage door. This is illustrated in Figure 4-14.
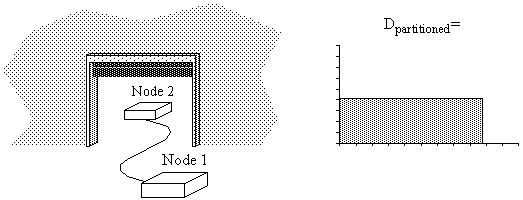
The mechanic has a problem because occasionally the garage door, which has a steel rim at the bottom, comes down hard enough to slice through the network cable and cause network partitioning. She decides to employ redundancy to reduce the risk of network partitioning. She adds a second link between the two nodes to accomplish this. How beneficial (or detrimental) redundancy will be is affected by where the second link is laid and how this is affected by the major failure modes. Figure 4-15 illustrates three possible failure modes and how Dpartitioned is affected by the redundant link.
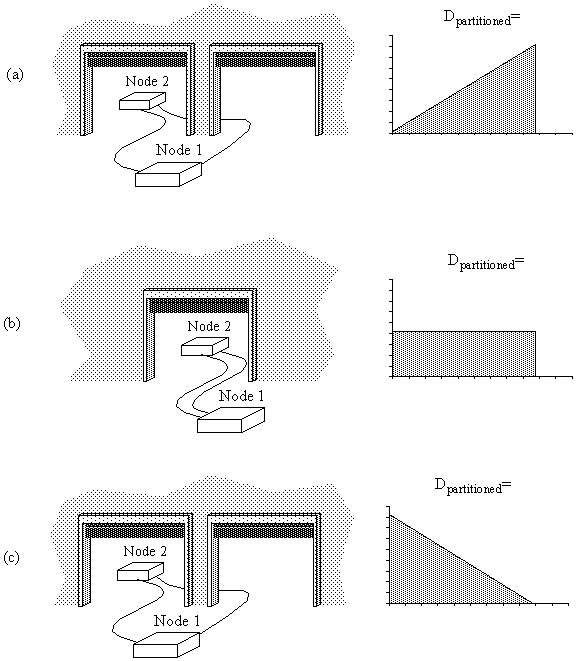
Figure 4-15 (a) shows a scenario where the failure of each link is independent of the other. Should a garage door come down too hard and sever one of the network links, the network remains unpartitioned. This is the best-case scenario for redundancy.
Figure 4-15 (b) shows a negation of redundancy effects through ill-placed cables. Should the garage door come down too hard, it will sever both network links simultaneously. In this case, the failure mode is completely dependent. However, since both network links will either remain okay or fail together, Dpartitioned is not affected by the addition of the redundant link.
Figure 4-15 (c) illustrates a worst-case scenario for redundancy. In this case, unbeknownst to the mechanic, the failure of one link also results in the failure of the other link (for some unspecified technical reason). Should either metal garage door sever either cable, the network loses both links and becomes partitioned. In this case, not only is the failure mode completely dependent, but a single link failure will result in network partitioning. Wiring a redundant cable through a second garage door increases the chance of a single link failure and thus network partitioning. The addition of a second link actually makes matters worse!
These scenarios illustrate the three basic forms of failure modes. In a practical application, the failure modes will take on different forms; some will be independent and others will be dependent to varying degrees. The collective influence of all failure modes will dictate the effectiveness of any given redundancy implementation.
A real-world example of a dependent failure mode is a recent aircraft crash into the Atlantic Ocean. A fire in the bulkhead burned the electronic cables controlling the aircraft, disabling all control from the cockpit. The aircraft was wired with redundant electrical systems, but the wires ran through the same conduits in the aircraft bulkhead. Because of this, the failure mode (fire) was dependent similar to the case in Figure 4-15 (b); the redundant system was insignificant. Had the wires been laid through separate conduits in different parts of the bulkhead, the failure mode may have been independent and the aircraft may not have crashed.
As with most engineering design issues, there is a trade off involved. The above aircraft example is a simplification of the issues. Routing the cables through separate conduits in the bulkhead will have positive and negative affects on failure modes other than fire in the bulkhead. The goal is to maximize independent failures and minimize dependent failures. The only way to do this is to know all of the failure modes involved and their interrelationships. Since this is impossible to know, the engineer must remember their calculated redundancy effects are only as good as their understanding of the failure modes.
The role of queues is very different for a single hop network versus a multiple hop network. This section investigates these differences. Section 4.3.1 describes the situation as it commonly exists for single hop networks. Section 4.3.2 extends this to the multiple hop case, and discusses differences between the two.
Measurement networks typically have a single shared link to which all nodes are connected. An example of this kind of network is illustrated in Figure 4-16. Assume for the moment there are no errors, and no retransmissions of any packets. In this simplified case, the queueing problem is trivial; any given node only needs to hold as many packets as it generates, until it has the opportunity to transmit them over the network.

For example, suppose in Figure 4-16 nodes 2 through 5 want to transmit a packet of transmission time Tpacket to node 1 once every T seconds, where
|
(4-3) |
To clarify, Tpacket is the time required to transmit the packet and depends upon network characteristics like the transmission rate, bit stuffing, signaling bits and delays, and so on. In this simplistic example, we assume Tpacket is constant.
In the worst case scenario, all four nodes generate and wish to transmit their packet simultaneously. Obviously only one node may transmit first, so the others need to store the packet in a buffer and wait their turn. Note equation (4-3) guarantees each node will have a chance to transmit its packet before it generates another. Consequently, each node only requires buffer space to hold one packet.
The above example illustrates one of the primary assumptions of this thesis. This assumption can be restated in a more general form: in any time T there must be sufficiently few packets n of sufficiently short transmission time Ti being generated and transmitted on any given link such that
|
(4-4) |
This simply states the network cannot transmit more information than it has capacity for. In some networks, such as ethernet [1], only a fraction of the total available bandwidth can be realistically used because repeated collisions and retransmissions of packets leads to a catastrophic state where no data gets through at all. Other networks, such as I2C [9] and CAN [7], use novel collision avoidance mechanisms which allow transmission of packets at almost the theoretical maximum rate.
For this thesis, the concern is how the presence of multiple hops affect the network capacity, queueing situation, and required buffer size.
To help analyze the situation, imagine a network as depicted in Figure 4-17.

Imagine each link in Figure 4-17 is capable of carrying n packets of constant transmission time Tpacket in a time period T. That is, our available bandwidth per link can be stated as so:
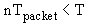
|
(4-5) |
Let's investigate an example situation. Assume nodes 2 - 5 are transmitting packets to node 1. If each node generates (0.3n) packets in each time period T, it appears there is ample bandwidth to carry all packets safely to node 1:
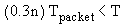
|
(4-6) |
However, upon closer examination, we discover this is not the case. For the given time period T, node 2 will have to transmit not only its own (0.3n) packets to node 1, but also forward the packets from node 3, 4, and 5 to node 1. Thus node 2 must deal with the traffic from four nodes in total (itself plus three other nodes):

|
(4-7) |
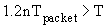
|
(4-8) |
Obviously it is impossible for node 2 to transmit all packets to node 1 in time T. If this level of packet generation is maintained, congestion and subsequent packet loss at node 2 will result.
Consequently, multiple links do not necessarily increase network capacity. The use of multiple links for redundancy or for increased bandwidth are mutually exclusive purposes. This thesis focuses on using extra links for the purpose of redundancy. For this reason, this thesis assumes network traffic remains sufficiently low such that any node can be the final destination of all packets generated in the network and there will be no congestion at any other node. In essence, this assumption guarantees multiple links will not be used to increase the network capacity. Using multiple links to increase network capacity requires additional functionality such as channel allocation and/or load balancing and is left as a topic for future research.
This assumption alone, however, does not eliminate congestion and possible buffer overflows. Congestion can still occur in networks with particularly devious topologies. We must, at this stage, bring the concept of buffer size into the picture.
Figure 4-18 has five nodes connected in a tree-like structure. Let us assume all packets generated by nodes 2-5 are destined for node 1. All assumptions stated above still apply. Suppose each node 2-5 sends a packet to node 1 simultaneously. The packet from node 2 will be sent directly to node 1. However, the packets from nodes 3-5 must first pass through node 2. If they all reach node 2 simultaneously, while node 2 is busy transmitting its own packet to node 1, node 2 must save the packets in a buffer until it has time to transmit them. If the buffer for node 2 is only big enough to hold one packet, then node 2's buffer would overflow and packets from nodes 3-5 would be lost.
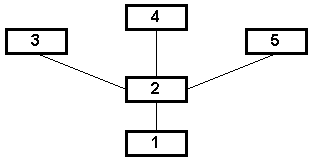
In order to guarantee no packets are lost in a network such as in Figure 4-18, one of two conditions must be met.
First, it must be guaranteed there is one and only one packet en route from source to destination at any time anywhere in the network. This assumption has fairly obvious and significant drawbacks. To name one, there is typically no way to synchronize nodes in a multi-link network in order to guarantee only one packet is transmitted at a time. Interestingly, one can see how, in a network with a single shared link, the link implicitly acts as an arbitrator to accomplish exactly this result; there can only ever be one packet en route at a time because there is only one link!
An alternative condition is to require all nodes to have sufficient buffer space to simultaneously hold a packet from every other node in the network. That is, if there are n nodes in the network, all nodes must have sufficient buffers to hold n packets. Since measurement networks have only limited memory, this condition is unrealistic.
Fortunately, a reduction of the required buffer size can be made if certain conditions are met. At a minimum, if a node shares links with n other nodes, it must have sufficient buffer space to accommodate n packets. In the worst case scenario this allows a node to receive packets from all neighbor nodes simultaneously. As one might expect, this condition alone is insufficient to guarantee zero packet loss. A network illustrating the problem is shown in Figure 4-19.
Imagine nodes 3 - 6 simultaneously send a packet to node 1. Furthermore, assume node 1 is simultaneously sending a packet up to node 2. Node 2 has buffer space equal to the number of neighbors it has, so it can hold all packets initially. However, after node 5 has transmitted its packet to node 2, it forwards node 6's packet to node 2 as well. But node 2's buffers are already full! If node 2 is not allowed the opportunity to empty its buffers after receiving packets in this fashion, its buffers will overflow.
The subsequent condition for our buffer optimization to work, therefore, is no single node may monopolize a medium for more than the time it takes to send a single packet. After it has sent a packet, other nodes on the medium must be allowed to transmit if they need to do so.
The above assumption is still fairly demanding of a measurement network. However, it is closer to being realizable and cost effective. For example, a network could be composed of mostly simple nodes with one or two interfaces, and a few more powerful nodes with three or more interfaces. This approach allows network designers to balance the benefits of multiple links against their additional complexity and cost.
Latency can be simply described as the difference between the time a packet is generated by a sender and the time the packet is received by the destination. Obviously, a packet traversing multiple hops in a measurement network will take longer than if it only needed to traverse a single hop (as in the single backbone scenario which measurement networks currently use). It is therefore of interest to this thesis to investigate how multiple hops affect latency.
In a network with a single shared medium, the latency is generally bounded by the frequency of packet generation. Observe the example network in Figure 4-20.

If all nodes in the network simultaneously wish to transmit a packet, the latency for each packet increases as each packet gets its turn. The latency for a given packet is directly and linearly related to the size and number of competing packets which "hog" the network before the packet can be transmitted. Therefore, the latency of a given packet n of transmission time Tn in a network such as Figure 4-20 may be expressed by equation (4- 9), where Ln is the total latency for packet n, and T1 to Tn-1 are the transmission times for the packets which "hog" the network before packet n is allowed to be transmitted.

|
(4-9) |
In a multi-hop network there are two distinct effects on equation (4-9).
First, because any simultaneous traffic could be distributed throughout the network, for any given link the value of n (i.e. the number of packets which "hog" the network before a given packet gets transmitted) may be lower. However, this may not always be true; in Figure 4-21, if nodes 2 - 5 are simultaneously sending packets to node 1, the link between node 2 and node 1 will carry the same traffic as the single backbone network in Figure 4- 20. Consequently, the latency situation between node 2 and node 1, due to congestion at node 2, will be roughly equivalent to the single backbone scenario.
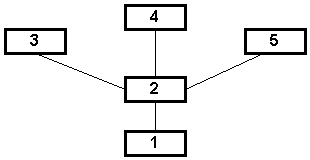
The second effect of multi-hop networks on latency is the number of times the packet must be transmitted. In a single backbone network, the packet is only transmitted once in order for it to reach its destination. In the multi-hop network, the packet must compete for and be transmitted on each link it traverses.
Thus, the total latency for a packet n traversing m hops to reach its destination can be generalized by the following formula.
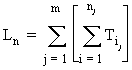
|
(4-10) |
It is reasonable to expect most hops will have small values for n in equation (4-10). However, this is not guaranteed. Multiple paths offer the opportunity to reduce the average value of n for a given link because, on average, packets can be distributed throughout the network instead of contending for a single link. However, multiple paths cannot guarantee this without some sort of load balancing or latency monitoring capabilities. Investigations into using multiple links to reduce latency are beyond the scope of this thesis and are left as topics for future research.
Obviously from equation (4-10) latency calculations are very dependent upon network topologies and traffic patterns. And equation (4-10) does not take into consideration the plethora of technology and implementation specific issues which also impact latency. Consequently, a more in depth investigation into latency in multi-hop networks is beyond the scope of this thesis and is left as a topic for future research.
This chapter analyzes the impact ad hoc routing protocols may have on measurement networks. The failure modes and failure PDFs of network links must be well understood to ensure redundancy has a positive effect on the overall network partitioning PDF. Failure modes should be analyzed and the network modified to minimize dependent failure modes. Redundancy can be used to procrastinate network partitioning, but cannot significantly extend the lifetime of the network beyond the expected lifetime of the individual links. Network maintenance operations can take advantage of non-critical link failures to repair failures before network partitioning occurs.
However, consideration must be given to the additional requirements of multiple hop networks with redundancy (namely multiple interfaces, increased cabling, and increased memory and/or CPU resources to handle network buffers). Furthermore, packet latency is an issue complicated by multiple hops and redundant links and should be investigated where latency is important.
Measurement networks are composed of simple computing devices connected by simple network technologies. The limited resources and capabilities of measurement networks represent a significant technological barrier to implementing routing protocols in these networks. The question is whether ad hoc routing protocols can be successfully implemented in measurement networks. Furthermore, do ad hoc routing protocols successfully mitigate or eliminate the problems of measurement networks as described in Section 1.3.
It is obviously usefull to show, with a high degree of certainty, the techniques and algorithms discussed in this thesis can be successfully implemented in a measurement network and that they achieve their intended goals. To demonstrate this, three criteria must be met: it must be shown it is possible to implement an algorithm under the constraints imposed upon it by a measurement network, the algorithm must be shown to operate properly, and the resulting network must demonstrate it is capable of overcoming the problems described in Section 1.3.
To accomplish this task, a simple network simulator was used. The simulator environment was designed to approximate a measurement network as defined in Section 1.3. A variant of DSR was implemented in the simulator and its performance analyzed under various conditions. DSR was selected for this exercise because it was found to perform the best out of four protocols implemented and tested by Broch [21] and does not require an auxiliary IMEP [25] layer. The following sections provide more detail regarding the simulator, DSR implementation, and the simulation results.
Section 5.1 describes the simulation environment used, including a discussion of the simulator's implementation of the network protocol stack. Section 5.2 discusses the network layer implementation in greater detail; the network layer is the layer primarily responsible for routing and is where the ad hoc routing protocol resides. Section 5.3 describes the simulation tests performed for this thesis and provides a discussion of their results. Finally, Section 5.4 summarizes the conclusions of this chapter.
For this exercise, the simulator must emulate the restrictive environment of a measurement network. If the simulated environment is not constructed carefully, the results may lose relevance. Section 5.1.1 discusses the simulator's operation in general. Section 5.1.2 discusses the application layer where network traffic is generated. Section 5.1.3 describes the physical layer and medium access issues.
In the simulator, time is broken down into discrete, equal-length time slices. During each time slice, all components are allowed to operate. Once processing is complete for a given time slice, the time is advanced by one time slice and the process is repeated.
The simulator is segmented into three layers as illustrated in Figure 5-1. The simulator was optimized to investigate network layer protocols. Consequently, the simulator's layers could be more descriptively called "everything above the network layer", "the network layer", and "everything below the network layer".
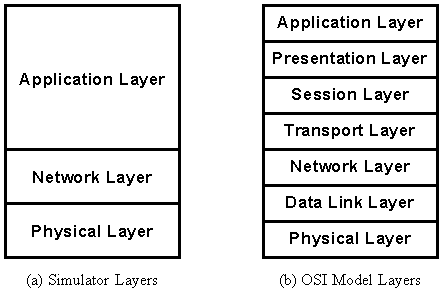
The application layer is responsible for generating packets and passing them to the network layer for delivery. The network layer is responsible for ensuring the delivery of packets across the network. The physical layer is responsible for delivery of the packet from one node to another across the media.
The astute reader will notice an absence of the data link layer in the simulator. The data link layer usually exists as an interface between the hardware and software. In larger systems such as IP, the data link layer implements additional protocols and procedures to perform MAC to network layer addresses resolution, format packets properly for the media, and so forth. In a measurement network, a separate data link layer represents a costly complication. Therefore, for this thesis, the network layer was assigned the additional task of performing data link layer operations. The network layer protocol, DSR, was modified to incorporate this added responsibility. This is discussed further in Section 5.2.3.
To simulate restricted memory resources, the various layers were constructed with small buffers, usually with space enough for only one or two packets. Cache sizes were similarly restricted to sizes of one or two entries. If cache sizes or buffers exceed their specified limit, the overflowing data is discarded.
Restricted CPU resources are harder to emulate with the simulator, so latency delays were introduced to mimic delays due to processing.
Link speeds, node configuration, and the other remaining characteristics of measurement networks are configurable settings of the simulator. These settings were selected for each scenario to closely match a real measurement network.
The packet generation models are based on the available modes of the StressNet system. StressNet is capable of reporting either at a constant frequency or when events occur based on event criteria. The start time of the constant frequency scheme has a random component to represent the somewhat random boot time of the StressNet nodes. For this thesis, the event criteria packet generation scheme is implemented in the simulator but is not used for any tests; the infrequency of the event criteria packets cause simulations to be less interesting and more difficult to measure characteristics such as convergence time.
In both packet generation models, the source and destination nodes are specified when the scenario is set up and does not change during the simulation. Other packet generation parameters are configurable as well, such as the frequency (for constant frequency) or the random factor (for event based) of packet generation and the packet size.
It should be noted in all simulations the total network traffic was designed to avoid exceeding overall network capacity. That is to say, the packet generation rate was kept sufficiently low as to allow all packets to flow through a single bottleneck link without significant risk of packet loss due to congestion. Without this criteria, the simulation begins to explore the ability of the routing protocol to increase throughput through the use of multiple links; this is a topic which is beyond the scope of this thesis and is left for future research. Nevertheless, it is always possible for localized congestion to occur when random route discovery and route error packets are taken into consideration. This is discussed further in Section 5.2.4.
The physical layer implements two components simultaneously; it implements the physical medium over which information is carried as well as the hardware interface to the medium. Consequently, if the hardware interface uses MAC addresses, the physical layer must implement and use them.
For this thesis, the physical layer was modeled after the I2C bus [9]. The I2C bus uses 7-bit MAC addresses. The I2C bus operates at a nominal rate of 100,000 bits per second. Each byte transmitted over the medium requires the transmission of 10 bits (8 data bits, and 2 signaling bits). Transmission overhead is required for the transmission of the destination MAC address. Link level acknowledgments are on a per-packet basis and are integrated into the transmission mechanism. That is, link level packet acknowledgments do not require the transmission of a separate packet.
The one significant way the simulator diverges from the I2C standard is the simulator uses 32-bit MAC addresses for convenience instead of 8-bit addresses. Packet sizes are larger as a result to accommodate the larger addresses.
When an error occurs on the physical layer causing packet corruption, the packet is retransmitted. The physical layer will attempt to transmit the packet a total of three times, after which it drops the packet and informs the network layer the link has presumably failed.
DSR [39] was implemented as the network layer protocol. DSR was implemented in a manner similar to how it might be implemented in an actual measurement network. In order to accomplish this, several modifications to the DSR protocol were made. Modifications included both the omission of features described in [39] as well as the addition of new and novel features.
Section 5.2.1 describes the DSR implementation in general. Section 5.2.2 describes features documented in [39] which were omitted. Section 5.2.3 describes two novel modifications to DSR merging the datalink layer with the network layer (and thus the DSR protocol). Finally, Section 5.2.4 describes how the DSR protocol and the simulator were configured to emulate a measurement network.
The authoritative definition of the DSR protocol can be found in [39] and is described briefly in Section 3.3. This section discusses in more detail the operation of DSR as implemented for this exercise.
DSR is a network layer protocol. As such, it is responsible for ensuring packets are transmitted across the network, via multiple intermediary networks if necessary, to reach their intended destination. The application layer passes packets to the network layer and does not see them again until they reach their destination. This behavior is illustrated in Figure 5-2.

Each hop knows exactly how to route each packet because the complete path is specified in the header of the packet.
There are four types of packets: route query, route reply, route error, and data. Each packet type treats the header information differently. The format of each packet type is shown in Figure 5-3.
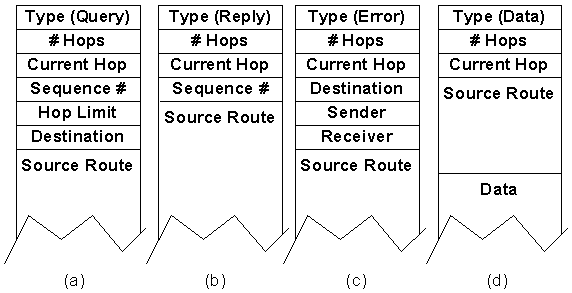
The # Hops is the number of addresses stored in the source route. The current hop is an index into the source route pointing to the current node. When a node receives a packet for forwarding, the node increments the current hop count in the header. This new current hop is used as an index into the source route to determine the next node along the packet's path. The packet is subsequently sent to this node (except for route query packets which are broadcast).
Figure 5-4 illustrates multiple snapshots of a network performing route discovery and data transmission; this may be useful for understanding the following detailed description of the packet types and protocol operation. In this example, node 1 is sending data to node 9.
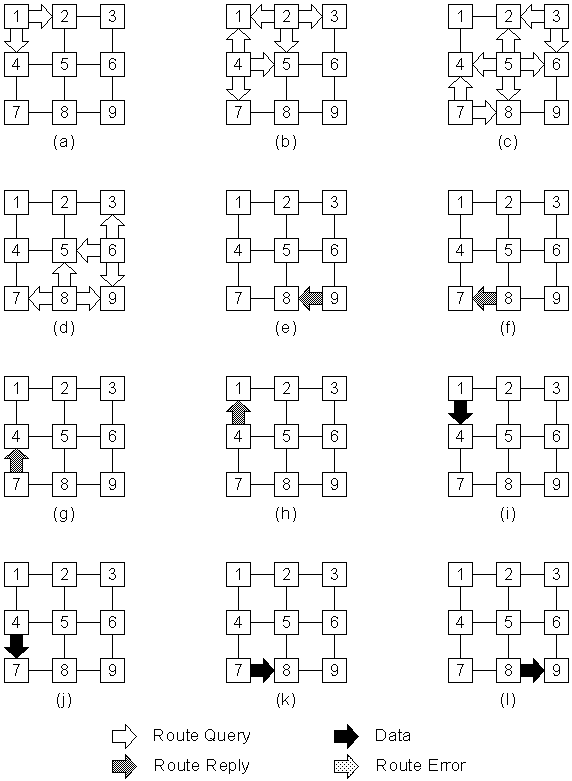
The route query packet is sent by a node wishing to discover a path to another node (Figure 5-4 a). It initially composes a route query packet with just its own network address in the source route, and both the current and total hop count set to 1. The packet is then broadcast to all neighboring nodes. Every node receiving a route query packet will append its own address to the source route, increment the current and total hop count, and re- broadcast the packet to all its neighbors (Figure 5-4 b-d).
If a node is already listed in the source route of a route query packet, the node has obviously already seen the route request. In this case, the packet is not rebroadcast and is ignored. Furthermore, each node caches the last three route request sequence number - source node pairs it has seen; if a route request packet matches a sequence number - source node pair in the cache, the node has seen a version of this route request and the packet is again ignored. Finally, if a route request packet's total hop count reaches the hop limit, the packet is no longer rebroadcast and is ignored.
When a route query packet reaches the intended destination (Figure 5-4 e), the destination node reverses the source route and returns a route reply packet. The total hop count and sequence number are copied from the route query packet, but of course the current hop number is reset to 1. If there are multiple paths from the source to destination, the destination may receive multiple route query packets. In this event, the destination node is normally expected to return a route reply packet for each route query (Figure 5-4 illustrates only a single route reply).
When a route reply packet reaches the original node requesting a route, the node may begin transmitting data packets (Figure 5-4 i-l). The newly discovered source route is copied verbatim into each data packet which is sent, enabling each packet to be routed by intermediary nodes. If the original node receives multiple route reply packets, the node must choose the "best" route. Because all routes are valid and only differ in their path, the choice of which route is "best" is arbitrary. In this simulation exercise, the "best" route is determined to be the first route heard by the node.
If a link should be rendered unfit to transmit packets, the node detecting the failed link will return a route error packet to the original node. This is illustrated in Figure 5-5. In this example, the data packet transmitted by node 7 to node 8 is lost due to a broken link (Figure 5-5 c).
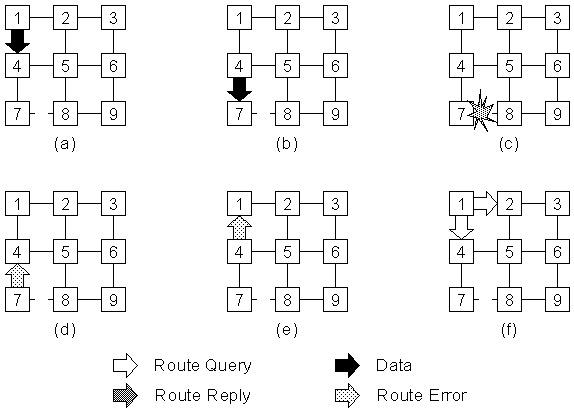
The route error packet contains the addresses of the node on either side of the failed link. However, in this implementation of DSR, this failed link information is ignored; a route error packet causes the original node to merely perform a new route discovery (Figure 5-5 f).
In this implementation, route discovery is a two-stage process. In the first stage, route query packets are sent with a hop limit of 1. That is, route query packets are sent only to the immediate neighbors of the original node and are not propagated throughout the network. This is to intended to reduce the overhead of route discovery where the destination is a direct neighbor of the source. After sending this 1-hop route query packet, the original node waits for a reply from one of its neighbors. If, after a time-out period, the original node has not received a route reply packet from one of its neighbors, the route query packet is re-broadcast, this time with a hop limit of 20. The astute reader will notice this limits the network topology to a maximum end-to-end hop count of 20. It also limits the life-span of the route query packet should the sequence number caching mechanism fail. The sequence number mechanism could fail if more than three route discovery operations are being performed by different nodes simultaneously, thereby overflowing the sequence number cache in some nodes.
All route query packets have a time-out value, after which a new route query packet may be transmitted by the original node. The time-out value is doubled every time to avoid excessive congestion while attempting to discover routes to far away or non-existent nodes. The time-out value is, nonetheless, limited to a maximum to ensure network responsiveness to changing conditions is preserved.
During normal operation, the DSR protocol requires a node to simultaneously queue both unicast and broadcast packets for transmission. This would normally require individual queues for each interface. However, as memory restrictions prevent this, the DSR layer implements only a single shared queue for all interfaces. However, this causes a problem when transmitting both regular and broadcast packets; a broadcast packet cannot be broadcast on some interfaces, and queued for later transmission on others which may be busy. Consequently, a fairly draconian and "dumb" method is used; a broadcast packet will not be transmitted on any interfaces until all interfaces are available (not transmitting) and the packet may be transmitted simultaneously on all interfaces. This may result in slightly longer route discovery operations because nodes must wait for all of their network interfaces to be available. However, this simplifies the network queueing situation significantly; nodes do not have to explicitly track which broadcast packets have been transmitted on which interfaces.
There are many operations, characteristics, and options of DSR as specified in [39] which were not included in this DSR implementation. Virtually all of them are removed to simplify the DSR implementation and reduce memory and CPU resource requirements. This section describes in detail which features are omitted.
The route cache is almost completely ignored; the only route a node remembers is the route it requires to send packets to one other node. In essence, the route cache is just big enough to hold a single route. Nodes do not reply to route queries from their route caches (where they return a route reply if they happen to know how to reach the destination). Nodes do not learn of new routes from packets being forwarded or overheard. However, they may modify their route cache upon overhearing a route error packet.
Piggybacking of data during route discovery is not implemented. This is where data is included in the route request, route reply, or route error packet. The goal of piggybacking is to reduce bandwidth and the cost of separate data and route discovery packets.
This implementation does not make any intelligent decision upon discovering multiple routes to a destination. The first route to be returned to the node is the one which is used. Presumably the first route returned is also the shortest and/or the fastest.
This DSR implementation does not inherently implement a retransmission mechanism. This functionality is left to the interface (link-layer) handling software and hardware. This division of functionality was done for two reasons. First, some hardware may perform automatic acknowledgment and retransmissions as part of the interface. Secondly, the interface software in the simulation handles retransmission using the interface's packet buffer. The per-interface packet buffer is described in more detail in Section 5.2.4.
Broadcast packets are never acknowledged nor resent.
The packet header format is simplified greatly to reduce its size and complexity. Only the fields used by this implementation are included. It might be noted since this implementation does not use the sending and receiving node information in route error packets, this information could additionally be removed from the protocol.
Bidirectional links are not only assumed, but are required by this implementation.
This implementation does not attempt packet salvaging of any sort. This is where a packet with an invalid source route is given a new source route by an intermediary node. The intermediary node presumably knows a valid route to the destination for the packet to take.
In most networks, a physical interface device connected to a medium must have a unique address. The interface device uses this Medium Access (MAC) address to differentiate packets intended for itself from packets intended for other interfaces. Whenever a packet is transmitted on the medium, it must be addressed with a destination address. Examples of networks which operate in this manner include Ethernet, I2C, and CAN to name a few.
A problem arises when a network layer needs to transmit a packet to another node. The problem is the network layer knows its own network address, its MAC address, and the destination's network address. What it does not inherently know is the destination's MAC address. Unfortunately, when the networking layer passes a packet to the MAC layer for transmission, it must tell the MAC layer the MAC address of the destination. As one soon realizes, the network layer is in somewhat of a quandary.
In IP networks over ethernet, a simple protocol exists at the data link layer whereby a node may broadcast a "who-is" packet with the destination's network address included. The destination will then reply with a packet telling the original node its MAC address. The original node receives this reply and adds the network and MAC pair to its MAC/network address mapping cache.
Unfortunately, in measurement networks, memory is at a premium; supporting MAC to network address caches introduces a significant complication, not to mention the extra code and protocols required to perform the operation.
While implementing DSR for this thesis, this problem was solved in two ways, believed to be novel in their design. Both work by extending the DSR protocol to include the MAC layer. These two modifications to the DSR protocol are described in the following sections.
This modification generalizes the concept of multiple interfaces and treats all interfaces as a single broadcasting interface. Whenever a packet must be sent to a destination node, the packet is addressed with the destination node's network address, and the packet is broadcast on all mediums (interfaces) connected to the node. The destination node presumably resides on at least one of the mediums and should hear the broadcast packet.
In this way, MAC layer addresses are rendered moot; the only MAC address ever used is the broadcast address. This simplifies DSR significantly and removes any requirement for MAC to network layer address mapping.
There are significant disadvantages to this method, however. First, since it is assumed nodes will typically have multiple interfaces connecting them to multiple mediums, broadcasting every packet on every medium will obviously waste bandwidth. Secondly, on many mediums, broadcast packets are not acknowledged at the link layer, even when such a facility exists for non-broadcast packets. Losing the link layer acknowledgment capability eliminates any hope for link layer retransmissions and may affect implementation details at the network layer. More importantly, however, is the loss of the ability to detect link failures and subsequently generate route error packets. Consequently, if this method is used, there must be an alternate means of determining link failure.
This method was implemented in the simulator and shown to work. Figure 5-6 illustrates this method in operation. The simulator does not detect dropped or corrupted broadcast packets at the physical layer. However, the simulator assumes the physical layer has a mythical method of detecting link failures in order to notify the network layer and subsequently generate route error packets.
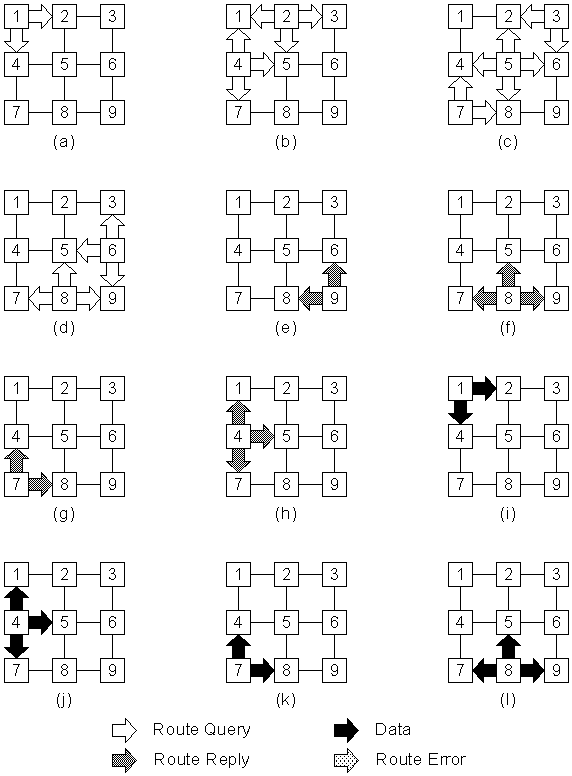
This modification extends the concept of source routing to include MAC layer addresses. Whenever a node includes itself in a packet's source route during route discovery, it not only appends its network address, but also the MAC address of the interface on which the packet was received and the MAC address of the interface on which the packet is transmitted. In this way, the MAC to network address mapping is performed simultaneously with route discovery. However, instead of being stored in caches at each node, this information is stored in the source route, a trick which complements DSR's design nicely.
In fact, with this arrangement the networking layer address may be safely removed altogether from the source route! The source route then becomes a list of MAC source:destination addresses pairs.
This method as stated breaks down in the case where a single node has two interfaces, connected to separate mediums, but with identical MAC addresses. In networks using I2C or CAN, this is not only possible but fairly probable. In this case, some way of distinguishing the interfaces from one another is required as the MAC address alone is insufficient.
Fortunately, the node may supply this information unilaterally and arbitrarily. The information may be ambiguous and meaningless to all other nodes in the network; it merely needs to be sufficient for the node in question to route a packet to the proper interface. Thus this identifier may be the memory/port address of the network interface, or something as simple as an index telling the node which of several interfaces to send the packet to.
While it could be argued including MAC addresses and interface identifiers in the source route adds substantially more information into the source route, this may not necessarily translate into larger packet headers. For example, suppose a network was constructed whereby nodes had 32-bit network addresses and were connected using I2C links. In this example, using only network addresses in the source route requires 32-bits per hop. I2C MAC Addresses, in contrast, are only 7 bits long. Lets assume each node may have no more than four interfaces, and the distinction between them is made by including a 2-bit interface ID in the source route. In this scenario, the complete source:destination MAC address pair only consumes 2*(7+2)=18 bits, leaving a whopping 14 bits left over for extra information or checksums as compared to the 32-bit network address.
It should be noted network addresses are still required during route discovery. The source node presumably knows the network address of the destination, not the MAC address. However, only the final destination network address needs to be included in the packet; all other hops may be referenced merely by their MAC layer address and interface ID.
One drawback of removing the network layer address from the source route is the loss of MAC to network layer address mapping. Depending on the design and purpose of the network, this may be of a concern (for example, to perform certain diagnostic operations on the network).
This method was successfully implemented in the simulator; its operation is illustrated in Figure 5-7. In the simulator, MAC addresses are assumed to be unique over the entire network and, as such, may also serve as the interface ID. The simulator includes both network and MAC address information in the source route to facilitate operations such as post-processing and statistical analysis. This results in the packets being slightly larger than they may be in an optimized measurement network.

There were two driving factors in choosing the settings for the simulator and simulation scenarios: what is reasonable to expect from a measurement network, and what is required to conform to the assumptions and limitations of this thesis. Many of the simulator settings have already been discussed in other sections. This section merely includes important but thus far neglected details of the simulation exercise.
Sections 4.3 presents various arguments relating to the queueing situation within nodes. In particular, three conditions are required to eliminate the risk of buffer overflows due to congestion.
First, the total network traffic must remain sufficiently low so as to be able to traverse a single bottleneck without buffer overflows. This is nearly impossible to accomplish using the DSR protocol because the route discovery mechanism generates a potentially large number of packets at potentially inopportune times. Consequently, this simulation exercise cannot avoid the occasional loss of data due to congestion and buffer overflows. However, the packet generation schemes were configured to avoid congestion caused by regular data traffic; the risk of congestion only exists during route discovery or as the result of a link failure.
Secondly, each node must be able to simultaneously receive and store a packet on every one of its interfaces. This is accomplished by giving each interface an individual buffer able to hold a single packet. This requires more resources from nodes with more interfaces, but this assumption is not unreasonable to expect in a real-world implementation.
Lastly, interfaces connected to a single medium should take turns transmitting and should not monopolize a given medium for more time than is required to transmit a single packet. This is accomplished in the simulator by implementing a link-layer round-robin transmission mechanism. However, despite this mechanism being available, it is largely ignored because random delays at the interface level all but guarantee no two interfaces will compete for the same medium at the same time. If a round-robin medium sharing mechanism is infeasible in an actual implementation, introducing intelligent delays into the transmission algorithm may accomplish a similar result. For example, after transmitting a packet, a node may be required to hold off for a period of time before attempting to transmit again.
All of the buffers in the DSR implementation are small; the route cache is large enough for a single route, the network-layer buffer is large enough to hold two packets (one for packets being forwarded, one for packets the node itself is generating), and the route request sequence number cache can only hold 3 sequence number / source address pairs. Essentially, buffer space is reduced to an absolute minimum. The only way to reduce buffer memory smaller than as implemented in the simulator is to either reduce the maximum packet size or sacrifice interface buffers (in which case increased packet loss due to congestion may occur).
The send buffer in nodes, which holds packets awaiting transmission pending route discovery operations, is large enough to hold only a single packet. If subsequent packets are generated by the application layer before the route discovery operation is complete, the subsequent packets will be dropped.
Link data rates are modeled after the I2C network used by the StressNet system; the bitrate was set at 100,000 bits per second, with a byte requiring the transmission of 10 bits including start/stop and acknowledgment bits.
Various tests were run on the simulator. These tests were intended to exercise the DSR algorithm, ensure its proper functionality, and determine how well the resulting network overcomes the problems described in Section 1.3. A secondary goal was to provide some indication of the potential of the DSR protocol as implemented in its scaled-down and restricted state.
Six test networks were used containing various node counts and topologies. The networks are illustrated in Figure 5-8. The network topologies were designed to represent two extremes in redundancy; many redundant paths and no redundant paths. Within these two extremes, node counts of 4, 9, and 16 were used. All six networks were used in each test unless otherwise noted.
Network topologies using common links connected to three or more nodes were not used. This was done because the tools available for this thesis favored networks with only two nodes per link. It would be interesting to investigate the impact of three or more nodes per network link on the operation of the protocol. This is left as a topic for future research.
Only one traffic generation scheme was used in all tests: all nodes generated packets at a constant rate and all packets in the network were sent to a single sink node. This scheme was selected to emulate the most commonly used configuration of the StressNet system (based on informal observations of StressNet applications by the author). Investigations into the effects of using alternative traffic generation schemes are left as a topic for future research. For example, in the case of network E, 15 nodes sent a constant packet stream to the 16th sink node. In Figure 5-8, the sink node is shaded. For networks A, C and E, the sink node was the bottom right corner node. For networks B, D and F, the sink node was the node on the furthest right.
The following sections describe each test and related results in detail.
The start-up or "boot" test shows the network is capable of operating shortly after being turned on. The only information the nodes have upon start-up is their network address and the MAC address of any connected interfaces. This test shows the protocol is capable of discovering routes on demand as required. This test could also be called the "self- configuration" test because it demonstrates DSR's ability to automatically discover routing information and route packets, a task usually requiring human intervention to accomplish.
1000 tests were run on each network from Figure 5-8. Each simulation ran for 60 simulated seconds. The convergence time for each test was measured and plotted on a graph (Figure 5-9 and Figure 5-10 below). The convergence time was measured from the time the simulation began to the point when every node in the network had successfully completed a source discovery operation (at this point, every node can address its packets with a valid source route to its destination).
The number of packets sent and received successfully by the application layer were measured. It was found, across the tests and network topologies, 92.8% of packets were successfully delivered from source to destination. This measurement is slightly lower than it should be because packets in-flight at the end of the 60 second test were counted as undelivered. Nevertheless, network connectivity was clearly provided.
From this test, it can be concluded DSR is capable of "self-configuring" the network both quickly and automatically. Furthermore, the tests on networks B, D and F demonstrate DSR is capable of handling multiple links laid end to end to span distances greater than individual links could span alone. It can also be concluded from this test DSR is capable of operating without any central support structure.
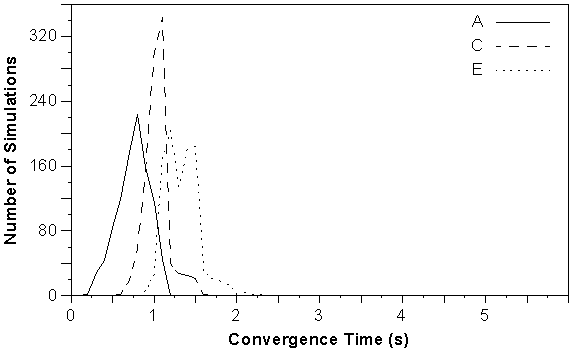
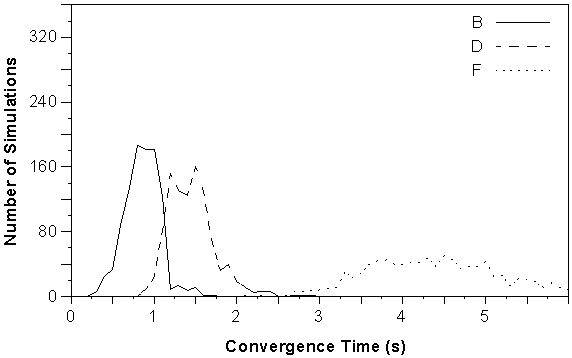
The link failure test demonstrates the network's ability to automatically re-route packets in the event of a link or node failure.
In this test only networks A, C, and E from Figure 5-8 were used (networks B, D, and F have no redundancy which make them useless for this test). In each test, the destination node (sink) for all traffic had two links to it. At the start of the test (time = 0s), one of these links was disabled; this forced all route discovery operations to find and use the second link. The network was given 30 simulated seconds to converge. At time = 30s, the first link was re-enabled and the second link was disabled to simulate a failure. This forced all nodes to be notified of the failed link and discover an alternate route (in this case, over the first link). The network was given a further 30 simulated seconds to run and the convergence time was measured. The first convergence after time = 30s was assumed to be the convergence time in response to the link failure. The convergence distribution from 1000 simulations on each network is graphed in Figure 5-11.
From this test, it can be concluded DSR is capable of responding quickly to changes in network topology. It does so by taking advantage of redundant links and re-routing traffic around problem areas.
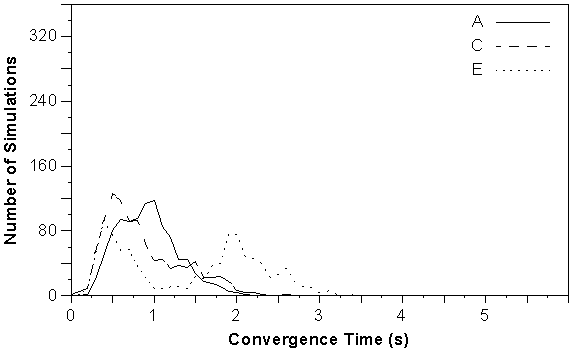
The new link / node test demonstrates the ability of a new link or node to become integrated into the network.
In this test, one node was isolated from the network. This was accomplished by disabling all of its connected links at time = 0. For networks B, D and F, the isolated node was the node furthest from the sink node (i.e. the one on the far left). For networks A, C and E, the isolated node was the top-left node. The network was then given 30 simulated seconds to converge.
At time = 30s, the isolated node was introduced into the network by re-enabling its links. The time was measured from this point until network convergence was achieved. Network convergence in this context means the new node successfully discovered a route to its desired destination (the sink).
1000 tests were run on each network from Figure 5-8, and each simulation ran for a total of 60 simulated seconds. This gave the newly introduced node 30 seconds to discover its required route and for the network to compensate for the new node.
Figure 5-12 and Figure 5-13 graph the convergence times for each network after the introduction of the new node. As one might expect, these graphs appear similar to Figure 5-9 and Figure 5-10, except the convergence times are faster. This is as expected; whereas Figure 5-9 and Figure 5-10 show the time required for multiple nodes to perform route discovery operations, Figure 5-12 and Figure 5-13 show the time required for only one node to perform route discovery.
From this test, it can be concluded DSR is capable of integrating and taking advantage of new links and nodes introduced into the network at arbitrary times.
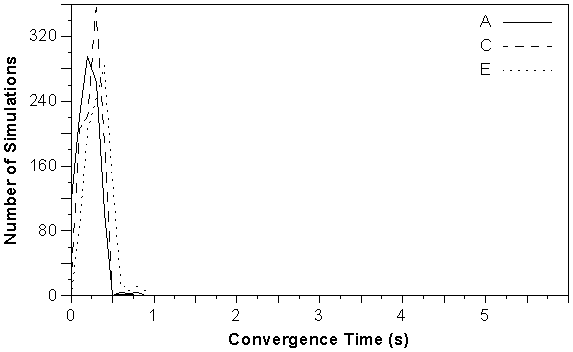
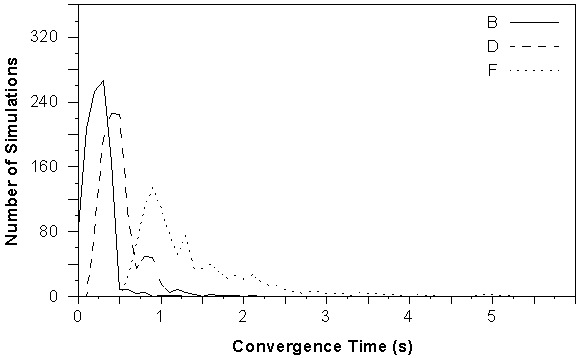
This chapter shows, through the use of a simulator, implementing an ad hoc routing protocol in a measurement network is possible, the resulting protocol behaves as expected, and this mitigates or eliminates the problems as described in Section 1.3.
In particular, this chapter describes how a simplified version of the DSR protocol was successfully implemented for a simulated measurement network designed to reflect the StressNet product. Two novel techniques for integrating MAC addresses into DSR were developed to aid the integration of DSR with the measurement network environment.
Several simulation scenarios successfully demonstrate the ad hoc routing protocol implementation works as expected. Furthermore, the ad hoc routing protocol is shown to mitigate or eliminate the problems of measurement networks as described in Section 1.3. The network is capable of "self configuring" the network both quickly and automatically. The network is capable of handling multiple links laid end to end to span distances grater than individual links could span alone. The network is capable of operating without any central support structure. The network is capable of responding quickly to changes in network topologies by taking advantage of redundant links and re-routing traffic around problem areas. Finally, the network is capable of integrating and taking advantage of new links and nodes introduced into the network at arbitrary times.
Measurement networks are networks of simple computing devices designed to monitor and report the status of a test subject. Measurement networks, as they exist today, have a variety of problems involving their construction, operation, and maintenance. This thesis and the accompanying research were instigated to find ways these problems could be mitigated or eliminated by implementing routing protocols in the network.
This thesis reviews the major networking philosophies and routing technologies of present day. In particular, this thesis reviews the major ad hoc routing protocols and investigates their relative appropriateness for implementation in measurement networks.
This thesis reviews the impact of adding ad hoc routing protocols to measurement networks, including the effects of multiple interfaces, redundancy, and queueing considerations. It is expected the requirement of multiple interfaces increases the complexity and cost of nodes. The effects of redundancy are multi-faceted and emphasize the importance of understanding failure modes and failure PDFs. The effects of multiple hops introduce new design considerations regarding latency and buffer size.
This thesis implements an ad hoc routing protocol, DSR, in a simulated measurement network. Two novel modifications to the DSR protocol were devised and implemented to address medium access concerns. This exercise shows implementing a modified ad hoc routing protocol in a measurement network is possible. Several tests were conducted using the simulator to show the ad hoc routing protocol operated as expected and fulfills the requirements of this thesis. The network was capable of "self configuring" the network both quickly and automatically. The network was capable of handling multiple links laid end to end to span distances grater than individual links could span alone. The network was capable of operating without any central support structure. The network was capable of responding quickly to changes in network topologies by taking advantage of redundant links and re-routing traffic around problem areas. Finally, the network was capable of integrating and taking advantage of new links and nodes introduced into the network at arbitrary times.
The simulator constructed for this thesis has several shortcomings which could be improved upon. The simulator is tick-based and would be more efficient, more accurate, and easier to work with if it was event-based instead. The simulator was written in C and made extensive use of pointers. This lead to problems finding bugs, especially when the bug occurred infrequently. Using a language with better compile or run-time error checking such as C++ or Java may mitigate this problem. It would be useful for research and debugging purposes to move the network module (including the routing protocol) between the simulator and an actual measurement network. This requires the interface to the network module to be standardized and designed to represent an actual measurement network.
This thesis highlights many opportunities for future research. Investigations into the behavior of measurement networks using ad hoc routing protocols could be made using varying traffic generation schemes and different network topologies and larger node counts. Extensions to ad hoc routing protocols could be investigated to increase network throughput and reduce latency through the use of multiple redundant network links (this requires load balancing and/or channel allocation features to be included in the protocol). Finally, networks intolerant of delays or lost packets, such as control networks, would benefit from investigations into guaranteed delivery and maximum latency of packets.
[1] 802.3, 1998 Edition, Institute of Electrical and Electronics Engineers, Inc., 1998.
[2] 802.5, 1998 Edition, Institute of Electrical and Electronics Engineers, Inc., 1998.
[3] 80C652/83C652 CMOS single-chip 8-bit microcontrollers, Philips Semiconductors, December 5, 1997.
[4] CAN Physical Layer, CAN in Automation, Weighselgarten 26, D-91058 Erlangen, Denmark. http://www.can-cia.de
[5] CAN Implementation, CAN in Automation, Weighselgarten 26, D-91058 Erlangen, Denmark. http://www.can-cia.de
[6] CANopen, CAN in Automation, Weighselgarten 26, D-91058 Erlangen, Denmark. http://www.can-cia.de
[7] CAN Specification 2.0, Part A, CAN in Automation, Weighselgarten 26, D-91058 Erlangen, Denmark. http://www.can-cia.de
[8] CAN Specification 2.0, Part B, CAN in Automation, Weighselgarten 26, D-91058 Erlangen, Denmark. http://www.can-cia.de
[9] I2C-Bus Specification, Version 2.1, Philips Semiconductors, January, 2000.
[10] Internet Protocol, RFC 791, Information Sciences Institute, September 1981.
[11] M68HC11 Reference Manual, Revision 3.0, M68HC11RM/AD, Motorola, Inc., 1996.
[12] MCS 51 Microcontroller Family User's Manual, 272383-002, Intel Corporation, February, 1994.
[13] PIC12C5XX Datasheet, DS40139E, Microchip Technology Incorporated, November, 1999.
[14] George Aggelou, Rahim Tafazolli, Relative Distance Micro-discovery Ad Hoc Routing (RDMAR) Protocol, Internet Draft, draft-ietf-manet-rdmar-00.txt, September 13, 1999. Work in progress.
[15] Bernard Aboba, Mark A. Beadles, The Network Access Identifier, RFC 2486, January 1999.
[16] Bernard Aboba, Glen Zorn, Criteria for Evaluating Roaming Protocols, RFC 2477, January 1999.
[17] G. Ahn, Andrew Cambell, Seoung-Bum Lee, X. Zhang, INSIGNIA, Internet Draft, draft-ietf-manet-insignia-01.txt, October, 1999. Work in progress.
[18] F. Baker, Requirements for IP Version 4 Routers, RFC 1812, June, 1995.
[19] J. Bound, M. Carney, C. Perkins, Dynamic Host Configuration Protocol for IPv6 (DHCPv6), Internet Draft, draft-ietf-dhc-dhcpv6-16.txt, November 22, 2000. Work in progress.
[20] Jim Bound, M. Carney, Charles Perkins, Extensions for the Dynamic Host Configuration Protocol for IPv6, Internet Draft, draft-ietf-dhc-dhcpv6ext-12.txt, May 5, 2000. Work in progress.
[21] Josh Broch, David A. Maltz, David B. Johnson, Yih-Chun Hu, Jorjeta Jetcheva, A Performance Comparison of Multi-Hop Wireless Ad Hoc Network Routing Protocols, Proceedings of the Fourth Annual ACM/IEEE International Conference on Mobile Computing and Networking (MobiCom `98), October 25, 1998.
[22] Douglas E. Comer, David L. Stevens, Internetworking with TCP/IP Volume II, Prentice-Hall, 1991.
[23] A. Conta, S. Deering, Internet Control Message Protocol (ICMPv6) for the Internet Protocol Version 6 (IPv6) Specification, RFC 2463, December 1998.
[24] S. Corson, J. Macker, Routing Protocol Performance Issues and Evaluation Considerations, RFC 2501, January, 1999.
[25] S. Corson, S. Papademetriou, P. Papadopoulos, V. Park, A. Qayyum, An Internet MANET Encapsulation Protocol (IMEP) Specification, Internet Draft, draft-ietf- manet-imep-spec-01.txt, August 7, 1998. Work in progress.
[26] S. Deering, R. Hinden, Internet Protocol, Version 6 (IPv6) Specification, RFC 2460, December 1998.
[27] Jay L. Devore, Probability and Statistics for Engineering and the Sciences, Second Edition, pp 47 - 52, Brooks/Cole Publishing Company, 1987.
[28] Rohit Dube, Cynthia Rais, Kuang-Yeh Wang, Satish Tripathi, Signal Stability based Adaptive Routing (SSA) for Ad-Hoc Mobile Networks, IEEE Personal Communications, February, 1997.
[29] Harry J. R. Dutton, Peter Lenhard, Asynchronous Transfer Mode, Prentice Hall, 1995.
[30] J. Garcia-Luna-Aceves, Marcelo Spohn, David Beyer, Source Tree Adaptive Routing (STAR) Protocol, Internet Draft, draft-ietf-manet-star-00.txt, October 22, 1999. Work in progress.
[31] Mario Gerla, Guangyu Pei, Xiaoyan Hong, Tsu-Wei Chen, Fisheye State Routing Protocol (FSR) for Ad Hoc Networks, Internet Draft, draft-ietf-manet-fsr-00.txt, November 17, 2000. Work in progress.
[32] Mario Gerla, Xiaoyan Hong, Li Ma, Guangyu Pei, Landmark Routing Protocol (LANMAR) for Large Scale Ad Hoc Networks, Internet Draft, draft-ietf-manet- lanmar-00.txt, November 17, 2000. Work in progress.
[33] Z. Haas, M. Pearlman, The Zone Routing Protocol (ZRP) for Ad Hoc Networks, Internet Draft, draft-ietf-manet-zone-zrp-01.txt, August, 1998. Work in progress.
[34] R. Hinden, S. Deering, IP Version 6 Addressing Architecture, RFC 1884, December 1995.
[35] Philippe Jacquet, Paul Muhlethaler, Amir Qayyum, Optimized Link State Routing Protocol, Internet Draft, draft-ietf-manet-olsr-03.txt, May 24, 2001. Work in progress.
[36] M. Jiang, J. Li, Y. C. Tay, Cluster Based Routing Protocol (CBRP) Functional Specification, Internet Draft, draft-ietf-manet-cbrp-spec-00.txt, August, 1998. Work in progress.
[37] David Johnson, Dynamic Source Routing in Ad Hoc Wireless Networks, Mobile Computing, Kluwer Academic Publishers, pp 153-181, 1996.
[38] David Johnson, David Maltz, Protocols for Adaptive Wireless and Mobile Networking, IEEE Personal Communications, Volume 3 Issue 1, February, 1996.
[39] David Johnson, David Maltz, Yih-Chun Hu, Jorjeta Jetcheva, The Dynamic Source Routing Protocol for Mobile Ad Hoc Networks, Internet Draft, draft-ietf-manet- dsr-04.txt, November 17, 2000. Work in progress.
[40] David Johnson, Charles Perkins, Mobility Support in IPv6, Internet Draft, draft- ietf-mobileip-ipv6-13.txt, November 17, 2000. Work in progress.
[41] Seoung-Bum Lee, Gahng-Seop Ahn, Xiaowei Zhang, Andrew Campbell, INSIGNIA: An IP-Based Quality of Service Framework for Mobile Ad Hoc Networks, Journal of Parallel and Distributed Computing, pp 374-406, December 15, 1999.
[42] B. Cameron Lesiuk, Routing in Ad Hoc Networks of Mobile Hosts, Mech590 Report, University of Victoria, December 2, 1998.
[43] G. Malkin, RIP Version 2, RFC 2453, November, 1998.
[44] Lavon Page, Probability for Engineering with Applications to Reliability, pp 49- 52,Computer Science Press, 1989.
[45] V. Park, S. Corson, A Performance Comparison of TORA and Ideal Link State Routing, Proceedings of IEEE Symposium on Computers and Communication `98, June, 1998.
[46] Vincent Park, Scott Corson, Temporally-Ordered Routing Algorithm (TORA) Version 1 Functional Specification, Internet Draft, draft-ietf-manet-tora-spec- 03.txt, November 24, 2000. Work in progress.
[47] Charles Perkins, IP Mobility Support for IPv4, revised, draft-ietf-mobileip- rfc2002-bis-03.txt, 20 September 2000. Work in progress.
[48] Charles E. Perkins, Pravin Bhagwat, Highly Dynamic Destination-Sequenced Distance-Vector Routing (DSDV) for Mobile Computers, Proceedings of the SIGCOMM `94 Conference on Communications, Architectures, Protocols and Applications, pp. 234-244, August, 1994
[49] Charles Perkins, David Johnson, Route Optimization in Mobile IP, Internet Draft, draft-ietf-mobileip-optim-10.txt, November 15, 2000, Work in progress.
[50] Charles Perkins, Elizabeth Royer, Samir Das, Ad Hoc On-Demand Distance Vector (AODV) Routing, Internet Draft, draft-ietf-manet-aodv-07.txt, November 24, 2000. Work in progress.
[51] Jacob Sharony, An Architecture for Mobile Radio Networks with Dynamically Changing Topology Using Virtual Subnets, Mobile Networks and Applications 1, pp 75-86, 1996.
[52] Jacob Sharony, A Mobile Radio Network Architecture with Dynamically Changing Topology Using Virtual Subnets, Proceedings of ICC `96, pp 807-812, 1996.
[53] Mark S. Taylor, William Waung, Mohsen Banan, Internetwork Mobility: The CDPD Approach, Prentice Hall, 1997.
[54] S. Thomson, T. Narten, IPv6 Stateless Address Autoconfiguration, RFC 1971, August 1996.
[55] C-K Toh, Wireless ATM and Ad-Hoc Networks, Kluwer Academic Publishers, 1997.
The StressNet measurement network is a collection of data gathering microprocessors connected by a single shared I2C backbone link. The network was originally designed to interface to strain gauges, but the generic analog to digital inputs can be interfaced to most transducers without problems.
The specifications of each node are as follows:
The peak overall network throughput is approximately 1000 samples per second. All data is sent by the data collecting nodes to a single data loging "sink" node. The sink node either writes the data to a flashdisk or transmits it to a laptop via an RS-232 interface. Each sample is timestamped and synchronized to a unified clock.